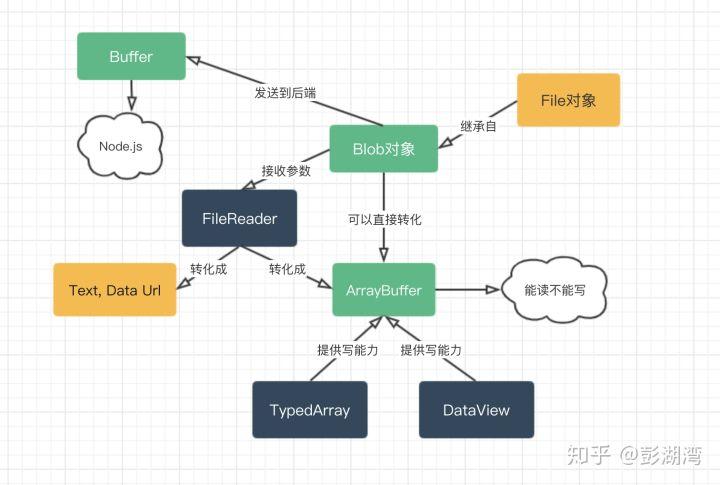
 > 图片来源:https://zhuanlan.zhihu.com/p/97768916 就像上图一样,这篇主要介绍Blob和ArrayBuffer相关的一些API之间的关系和用途,并不会详细介绍每个属性和方法,更多的是想讲述清楚一些概念。 Blob 我们在做预览本地图片需求时往往需要再`<Input>`中拿到File对象,再根据File生成一个Blob URL从而放进`img src`中显示。 其实`<input>`中的File实例对象和[`DataTransfer`](https://developer.mozilla.org/zh-CN/docs/Web/API/DataTransfer)对象(拖拽)是一个特殊的 Blob 实例,继承了Blob的属性和方法,只是增加了name和lastModifiedDate等专有属性。 Blob对象表示一个不可变、原始数据的类文件对象,它的数据可以按文本或二进制的格式进行读取,也可以转换成 ReadableStream(读写流) 来用于数据操作。 我们无法直接在 Blob 中更改数据,但我们可以通过 slice 将 Blob 分割成多个部分,从这些部分创建新的 Blob 对象,将它们组成新的 Blob。 ```js // 从字符串创建 Blob const blob = new Blob(['hello', ' ', 'world'], {type: 'text/plain'}); // 截取blob中不同下标之间的字节 const newBlob1 = blob.slice(0, 2) const newBlob2 = blob.slice(6, 8) // 组合成新的blob const newBlob3 = new Blob([newBlob1, ' ', newBlob2], {type: 'text/plain'}) newBlob3.text().then(console.log) // he wo ``` Blob URL 通过`URL.createObjectURL`可以为Blob生成Blob URL,最常用到的场景就是展示本地图片,将File生成的Blob URL放进img src中。 和较长的Base64格式的Data URL相比,Blob URL的长度显然不能够存储足够的信息,这也就意味着它只是类似于一个浏览器内部的“引用”。从这个角度看,Blob URL是一个浏览器自行制定的一个伪协议。也正是因为Blob数据是存储在内存中,它的生命周期和创建它的窗口中的` document ` 绑定,所以当用完了这个URL最好手动将其占用的内存释放。如果想要将信息留存下来作为url,将Blob对象转换为base64也是个方案。 FileReader 通过FileReader将Blob对象转为字符串、ArrayBuffer和base64; ```js // 将字符串转换成 Blob对象 const blob = new Blob(['中文字符串'], {type: 'text/plain'}); const reader = new FileReader(); // 将Blob 对象转换成字符串 reader.readAsText(blob, 'utf-8'); reader.onload = function (e) { console.info(reader.result); } // 将Blob 对象转换成 ArrayBuffer reader.readAsArrayBuffer(blob); reader.onload = function (e) { console.info(reader.result); } // 将Blob 对象转换成 base64 // FileReader.readAsDataURL() ``` Blob应用场景: - 将blob转为blob URL或data URL作媒体资源,即本地媒体文件显示; - 将blob通过slice进行分割从而实现分段上传; - canvas输出二进制图像数据;(`HTMLCanvasElement.toBlob`) - ... ----- ArrayBuffer、TypedArray和DataView 历史:为了充分利用3D图形API和GPU加速在canvas上渲染复杂图形,出现了WebGL(Web Graphics Library)。但因为JavaScript运行时中的数组并不存在类型,所以当WebGL底层与JavaScript之间传递数据时,需要为目标环境分配新数组,并以当前格式迭代,这将花费很多时间。 为了解决这个问题,则出现了定型数组(TypeArray)。通过定型数组JavaScript可以分配、读取、写入数组,并直接传给底层图形驱动程序,也可直接从底层获取。 既然定型数组赋予JavaScript跟底层进行数据交换的能力,那么就同样会出现与其他设备/网络进行二进制数据的交流,应对更复杂的场景,DataView也应运而生。 他们以数组的语法处理二进制数据,所以统称为二进制数组,TypedArray和DataView可以像C语言一样通过修改下标的方式直接操作内存。 ArrayBuffer对象存储原始的二进制数据,只是容器,需要TypedArray和DataView来读写。TypedArray视图用来读写单一类型的二进制数据,DataView视图用来读写复杂类型的二进制数据。 ArrayBuffer对象作为内存区域,可以存放多种类型的数据。同一段内存,不同数据有不同的解读方式,这就叫做“视图”(view); ```js const buffer = new ArrayBuffer(12); const x1 = new Int32Array(buffer); x1[0] = 1; const x2 = new Uint8Array(buffer); x2[0] = 2; x1[0] // 2 // 由于两个视图对应的是同一段内存,一个视图修改底层内存,会影响到另一个视图。 ``` 本来,在设计目的上,ArrayBuffer对象的各种TypedArray视图,是用来向网卡、声卡之类的本机设备传送数据,所以使用本机的字节序就可以了;但由于不同设备的操作系统中字节序的不同,所以需要DataView视图来做支持,它是用来处理网络设备传来的数据,可以自行设定大端字节序或小端字节序; 字节序 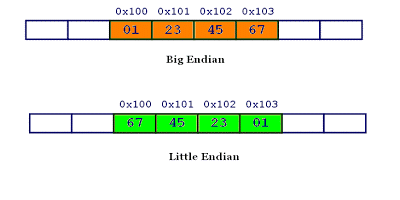 > 0x1234567的大端字节序和小端字节序的写法如上图,图片来源:https://www.ruanyifeng.com/blog/2016/11/byte-order.html - 大端字节序:高位字节在前,低位字节在后,这是人类读写数值的习惯顺序; - 小端字节序:低位字节在前,高位字节在后; 计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。(计算机内部都是使用小端字节这点不严谨,有人说是因为不同公司的习惯而已,因为X86和ARM架构是使用小端,但IBM的PowerPC是用大端,但这里不深究) 一般向外部写入数据是不需要管什么字节序的,直接用本机字节序即可,因为被写入的设备会有对应的驱动去判断字节序并正确读取数据。 ArrayBuffer ArrayBuffer对象用来表示通用的、固定长度的原始数据缓冲区,是一个普通的JavaScript构造函数,可用于内存中分配特定数量的字节空间。ArrayBuffer本身是可读不可写的,只是一个数据容器。 ```js const buf = new ArrayBuffer(16) // 在内存中分配16字节 console.log(buf.byteLength) // 16 ``` ArrayBuffer和JavaScript数组在使用上是完全不同的,有三个区别: - ArrayBuffer初始化后是固定大小的,并且可读不可写; - 数组里面可以放数字、字符串、布尔值以及对象和数组等,ArrayBuffer放0和1组成的二进制数据; - ArrayBuffer放在栈中,而Array放在堆中; TypeArray TypeArray是一个统称,实际使用的是特定元素类型的类型化数组构造函数; ```js const typedArray1 = new Int8Array(8); typedArray1[0] = 32; console.log(typedArray1); // Int8Array [32, 0, 0, 0, 0, 0, 0, 0] // 总共有 Int8Array(); Uint8Array(); Uint8ClampedArray(); Int16Array(); Uint16Array(); Int32Array(); Uint32Array(); Float32Array(); Float64Array(); ``` TypeArray操作的数组成员都必须是同一个数据类型。每一种视图的构造函数,都有一个BYTES_PER_ELEMENT属性,表示这种数据类型占据的字节数。 ```js Int8Array.BYTES_PER_ELEMENT // 1 Uint8Array.BYTES_PER_ELEMENT // 1 Uint8ClampedArray.BYTES_PER_ELEMENT // 1 Int16Array.BYTES_PER_ELEMENT // 2 Uint16Array.BYTES_PER_ELEMENT // 2 Int32Array.BYTES_PER_ELEMENT // 4 Uint32Array.BYTES_PER_ELEMENT // 4 Float32Array.BYTES_PER_ELEMENT // 4 Float64Array.BYTES_PER_ELEMENT // 8 ``` 由于视图的构造函数可以指定起始位置和长度,所以在同一段内存之中,可以依次生成不同类型的视图,这叫做“复合视图”。 ```js const buffer = new ArrayBuffer(24); const idView = new Uint32Array(buffer, 0, 1); const usernameView = new Uint8Array(buffer, 4, 16); const amountDueView = new Float32Array(buffer, 20, 1); ``` 二进制数组与字符串可以通过TextDecoder和TextEncoder来互相转换: ```js let uint8Array = new Uint8Array([72, 101, 108, 108, 111]); alert( new TextDecoder().decode(uint8Array) ); // Hello let uint8Array = new TextEncoder();.encode("Hello"); alert( uint8Array ); // 72,101,108,108,111 ``` DataView 专为文件I/O和网络I/O设计,对缓冲数据有高度的控制,但比其他视图性能差一点。跟TypeArray不同,DataView视图中允许存在多种类型,并且可以声明数据的字节序。 ```js const buffer = new ArrayBuffer(4); const view1 = new DataView(buffer); // 在不同位置设置不同类型数字 view1.setInt8(0, 42); view1.setInt16(1, 22) console.log(view1.getInt8(0)) // 42 console.log(view1.getInt16(1)) // 22 ``` 如果一次读取两个或两个以上字节,就必须明确数据的存储方式,到底是小端字节序还是大端字节序。默认情况下,DataView的get方法使用大端字节序解读数据; ```js // 小端字节序 const v1 = dv.getUint16(1, true); // 大端字节序 const v2 = dv.getUint16(3, false); // 大端字节序 const v3 = dv.getUint16(3); ``` Blob和ArratBuffer - Blob实际上就是针对文件设计出来的对象,而ArratBuffer针对需要传输的数据本身; - Blob主要解决媒体类型(MIME)的问题,ArratBuffer解决的是数据类型问题; - Blob是浏览器的api,ArratBuffer数据JavaScript中的标准,ArratBuffer是更底层的API,可以直接操作内存; 二进制数组操作场景 - 与底层显卡/外部设备进行二进制数据交互; - 利用SharedArrayBuffer在不同worker间共享内存(SharedArrayBuffer是ArrayBuffer的变体) - ... --- 如有错误,请务必留言告知,多谢~ > 参考资料:\ > [为什么视频网站的视频链接地址是blob?](https://juejin.cn/post/6844903880774385671) \ > [聊聊JS的二进制家族:Blob、ArrayBuffer和Buffer](https://zhuanlan.zhihu.com/p/97768916) \ > [ECMAScript 6 入门](https://es6.ruanyifeng.com/docs/arraybuffer) \ > [理解字节序](https://www.ruanyifeng.com/blog/2016/11/byte-order.html) \ > [二进制数据,文件](https://zh.javascript.info/blob) \ > [JavaScript高级程序设计(第4版)](https://www.ituring.com.cn/book/2472)
一、JavaScript作为解释型语言如何运行 - 引擎:负责整个JavaScript代码的编译和执行 - 编译器:做分词、语法解析析、生成引擎的执行代码(虽然JavaScript是解释型语言,但也是有编译过程的) - 作用域:管理和维护所有的声明和变量,并确定当前执行的代码对哪些变量有访问权限 > 作用域像一个辅助,编译时收集和管理变量,引擎执行时又要决定哪些变量能被访问 二、词法作用域 作用域分两种,词法作用域和动态作用域。大部分编程语言都使用第一种,包括JavaScript。词法作用域决定于变量和块作用域写在哪,它是在编译器解析词法的过程中就确定的。这个作用域的目的是辅助引擎编译和执行代码。 我的理解就是通过花括号来判断词法作用域,所以它是由代码书写的范围来决定的。 当然在JavaScript中可以通过with和eval来动态改变词法作用域,但不推荐,因为动态的作用域让引擎执行时不能更好地进行优化,所以会对性能造成影响。 三、函数作用域与闭包 是JavaScript最常见的作用域,一个函数的内部信息是对外隐藏的,但却能访问到外部信息,所以嵌套函数也会形成作用域链。利用这个特性可以使用自执行函数和闭包。 四、块作用域 不同于函数作用域,块作用域在JS中比较少见,以前只有在with和catch中会形成块作用域,内部的声明不能被外部引用。后来出现了let和const,它们声明的变量可以绑定在当前的花括号为块的作用域内,但并非生成块作用域。 五、声明提升 因为在编译器运行的过程中,会根据词法定义好作用域,在这个过程中一个变量的声明和赋值会被挺升至作用域顶部,而函数声明则更加厉害,声明和赋值都被提升。 这么做的目的个人猜测是因为JS作为一个灵活的脚本语言,这种设置能够智能地减少报错,但随着JS程序的扩大这种“小聪明”式的特性会带来一些意想不到的bug,与此类似的还有重复使用var声明同一变量,因为编译器会首先去查找在本作用域内是否早有声明,有则直接覆盖,并不是真正意义上的重复声明。为了解决这些副作用,es6推出了let和const来进行变量声明,摒弃了上面这些特性。 六、this指向 函数调用时,会创建一个执行上下文来记录所有信息,包括调用栈、调用方式等,而this就是其中一个属性,指向调用对象。这也意味着,this是在函数调用时决定的。 这也是为什么初学者会对this指向有疑惑,因为它不同于作用域链是在词法分析阶段就确认的,this是动态的,所以会让人困扰。而箭头函数正是为了解决这个问题,箭头函数不绑定调用对象,而是通过作用域链找到上一次层的this。 四个确定this指向的操作,按优先级顺序排列: 1. new绑定对象; 2. call、apply、bind显式绑定; 3. 对象属性直接调用; 4. 普通函数调用,隐式绑定全局对象,如果是严格模式则绑定undefined。 七、对象 以前我一直有两个疑惑,一是为什么JS有string、number等基础类型,他们与对象Object是不同的,为何它们也有属性和方法;二是为什么要有String、Number等构造器来构造对应的对象,却还需要所谓的基础类型? 第一个问题的原因是,当声明一个字符串如`var s = 'abc';`然后取`s.length`的时候,其实引擎自动帮我们将基础类型string转成String对象,所以自然就拥有里length属性。至于第二个问题,应该是考虑到内存的优化问题,毕竟基础类型只要存在栈上,也不像对象需要一个构造的过程,有性能的优势。 对象有属性描述符,顾名思义,就是对对象属性进行描述或者说规定。通常使用`Object.defineProperty`来进行配置,有`value、writable、enumerable、configurable`,通过这四个属性可以控制这个对象属性的增删改查。 [[GET]]是每个对象都会有的一个内置方法,用于访问属性,每次访问属性时都相当于`GET()`,有一个细节是,这个方法在本对象拿不到属性时,会尝试在原型链上查找。对应的还有个[[PUT]]内置方法,用于设置属性。 上面两个配置方法也可以被属性中的Getter和Setter来代替,这个同样也是由开发者通过`Object.defineProperty`修改的。其实Getter和Setter被称为访问描述符,通过设置对象属性的Getter和Setter也可以达到控制属性增删改查的效果,只是更灵活。 八、原型链 每个对象都有个[[prototype]]内置属性,他指向对象的原型,也就是原型链的形态。那么为什么需要原型呢?这是我一直的疑问,因为它虽然听起来很方便,可以向上找到属性,但却给这门语言带来了难以理解的复杂性。 如果说编程可以创造世界,那么我们为了避免重复描述,一般都会将一些通用描述“封装”起来,比如交通工具一般都有引擎,这是动力的来源,那么我们在创造汽车、轮船、飞机的时候就不需要去重复描述引擎这件事,因为是个交通工具就肯定有引擎的呀。那么我认为原型存在的目的就是去“封装”某些描述,这有点像类和类继承的概念。但是类继承其实是一个复制的方式,因为父子类是互不关联的,但原型链并不是。 而且由于JavaScript中一切皆对象,为了保证性能复制对象其实只是复制引用地址,所以自然而然地就出现原型链这种方式,以关联对象的方式达到“继承”的目的,原型链就是这种思想下的产物。 当你尝试去拿某个对象的属性时,会调用其内部方法[[GET]],它会先查找本对象,找不到再往原型链上找。 同样的设置属性值也是,当你设置`myObj.foo=123`时,会先查找myObj本身是否有,有则覆盖。myObj本身没有的话,我以前以为会直接添加,但实际并不是,它依然会先找原型链,如果上一级对象有相同属性则直接屏蔽掉它,再在myObj上添加,这听起来跟直接添加从结果上来说差别不大,但问题是当原型链上设置的同名属性是不可写的则这个操作不会进行下去,而是会报错(严格模式)或直接静默失败,如果原型链上设置了setter则会直接调用这个setter而不会在myObj上添加foo。使用defineProperty可以避免这个小问题。 九、Promise 在es6之前,异步操作都是跟JavaScript的宿主环境有关,所以异步操作往往是在的某个线程进行之后再通知js执行回调。但是es6引入了事件循环机制,同时把异步管理纳入了js引擎的范畴。 那么为什么需要引进时间循环或者说为什么需要promise呢?这主要是为了解决js传统的异步回调带来的问题:回调地狱以及回调的不确定性。promise的then和catch能清晰地描述异步步骤解决回调地狱。而promise.then只调用一次也避免了异步回调的不稳定性(回调的调用者可能不受控,可能被调用多次或者吞掉错误)。 promise意为承诺,承诺给你一个结果,拿到结果我就做接下来的事,而回调是将我要做的事告诉对方等他愿意做的时候再帮我做,他会做几次、会不会出错我都不确定。简单来说,用回调来处理异步事件是一件存在很多坑的事。 还有一些点,如promise.all解决多异步共享结果,race解决竞态,promise里只有同步操作也必须入队列解决同步代码导致执行顺序预期不正确。这些都是锦上添花的语法糖。 promise的错误处理有一点需要注意: ```js // Promise.resolve会将传入参数promise化,如果传入的参数带有then属性,则会直接将其promise化并展开调用 p = Promise.resolve(123) p.then((res) => { throw Error() // 报错 console.log(res) // !!这里永远不会执行 }, (err) => { // 我以为这里会执行,但不会。因为p.then实际会返回一个默认的Promise.resolve(undefined) // 所以p和p.then是两个单独的promise,故这个reject回调不会被调用 console.log('error 1') }).then(() => { console.log("这里会执行吗") // 并不会执行 // 实际这个then里会默认补充一个rejected回调: (err) => Promise.reject(err) // 所以报错error会继续传递下去 }).catch((err) => { // 这里才会catch到p.then的错误 console.log('error 2') }) // 结果:error 2 ``` 十、事件循环 JavaScript会维护一个执行栈,把所有函数的上下文合成一个栈帧压入栈,执行完后出栈,而关于异步的操作事件则是维护一个队列,循环去取出队列中的回调压入栈。 当执行栈清空后就开始清队列,规则是在每个循环中,不断对队列执行下面三个步骤: - 执行一次宏任务(所有运行在外部事件源的任务,这里指浏览器的DOM操作、Ajax、用户交互、History Api、定时器、script标签的执行) - 执行队列内所有的微任务(es6后加入的Promise和MutationObserver) - 渲染页面 ```js setTimeout(() => { console.log('setTimeout 1'); Promise.resolve().then(() => { console.log('Promise 3'); }).then(() => { console.log('Promise 4'); }); }); Promise.resolve().then(() => { console.log('Promise 1'); }).then(() => { console.log('Promise 2'); }); console.log('start') setTimeout(() => { console.log('setTimeout 2'); }); / 结果: "start" "Promise 1" "Promise 2" "setTimeout 1" "Promise 3" "Promise 4" "setTimeout 2" / ``` 这里有一点要注意,按我上面的循环步骤,应该至少要先执行一次宏任务(setTimeout)才对,为什么还是先执行了所有Promise的结果,原因是这段代码会运行在<script>标签里,而这个标签的运行是一次宏任务。所以我之前一直误解是微任务先执行。
首先需要说明下,TypeScript 是 JavaScript 的超集,这意味着任何 js 写出来的代码,ts 都必须能声明出对应的类型约束,这就导致 ts 可能会出现非常复杂的类型声明。而一般的强类型语言则没这样的问题,因为在一开始设计之初,那些无法用类型系统声明出来的接口压根就不允许创建。 并且,TypeScript 是结构化类型,有别于名义类型,任何类型是否契合取决于它的结构是否契合,而名义类型则是必须有严格的类型对应。 本文很多内容都是基于上面两点去思考的,下面进入正题。 一、关于枚举 1. 动态枚举 允许在枚举中初始化动态的数值,但字符串不行 ``` // 动态数值 enum A { Error = Math.random(), Yes = 3 9 } // 当带有字符串时则不可以 enum A { Error = Math.random(), // Error:含字符串值成员的枚举中不允许使用计算值 Yes = 'Yes', } ``` 2. 数字和字符串枚举的检查宽松度不同 ``` // 数字枚举的宽松检查 enum NoYes { No, Yes } function func(noYes: NoYes) {} func(33); // 并不会报类型错误! // 字符串枚举却报错 enum NoYes { No='No', Yes='Yes' } function func(noYes: NoYes) {} func('NO'); // Error: 类型“"NO"”的参数不能赋给类型“NoYes”的参数 ``` 之所以允许数字随意赋值给枚举,我猜也是因为允许动态数值枚举的关系,默认枚举可能为任意数字。 3. 作为对象 字符串和枚举值不兼容,但因为 ts 是结构性类型系统,枚举本身却又可以兼容对象 ``` enum NoYes { No = 'No', Yes = 'Yes', } function func(obj: { No: string }) { return obj.No; } func(NoYes); // 编译通过 ``` 4. 存在问题的双向映射 ``` enum Foo { a, b } // 编译后带来了双向映射的特性 var Foo; (function (Foo) { Foo[Foo["a"] = 0] = "a"; Foo[Foo["b"] = 1] = "b"; })(Foo || (Foo = {})); // 反向映射 Foo[0] === 'a' ``` 但当两个枚举都指向同一个数字时,会出现问题: ``` enum Foo { a = 0, b = 0 } Foo[0] === 'b' // 'a' 无法反向映射 ``` 如果是动态枚举,就更可能暴露这个问题了。 为什么有人不建议使用 enum? - 数字和字符串枚举的检查宽松度不同; - 双向映射存在问题; - ts enum 编译后的代码增加了复杂度,并不符合直觉,如果因此导致了 bug 会很难排查,因为一般人不认为编译器会出错; - 这些新加入的特性违背了 typescript 一开始承诺的”仅扩展类型“。 综上所述,很多人建议使用联合类型或 Object as const 来替代 enum,但用联合类型会带来很多魔法数字,用 Object 则需要通过 keyof 的方式来类型声明,多少有点不优雅。所以除非对 enum 的缺点完全无法容忍,目前还没有更好的替代方案。 二、重载为什么不能分开写 ts 中的重载,不同于传统的重载,只是函数签名的重载,并不提供类型约束功能。 ts 中的函数重载: ``` function foo(p: string); function foo(p: number); function foo(p: string | number) { ... }; ``` java中的重载: ``` public class Overloading { public int foo(){ System.out.println("test1"); return 1; } public void foo(int a){ System.out.println("test2"); } } ``` 不支持分开写重载的原因是: - 传统的重载是在编译时将重载函数拆分命名(func 拆分为 func1、func2),再在调用处修改命名,从而达到通过参数区分调用的效果。而 JavaScript 在运行时可以随时修改类型,如果依然采用传统重载的编译规则,可能会导致不可预期的问题。 - ts 与 js 可交互性受影响,如果像传统重载那样,将函数拆分,在 js 脚本里调用 ts 中的重载方法将会有问题。 - typescript 是结构化类型,如果一个函数同时满足多个重载,那么最终无法确定要选择调用哪一个。 - 就算上面的问题都解决了,这也不符合 ts 的[设计原则](https://github.com/Microsoft/TypeScript/wiki/TypeScript-Design-Goalsgoals),ts 从设计上希望保留 js 完整的运行时行为,并且在语法设计上与当前和未来的 ECMAScript 提案保持一致。 所以 ts 目前及未来都不会支持传统重载,并且[传统重载也存在自己的问题](https://gitbook.cn/books/5d68a6e202d5047dfba972c8/index.html),并非完美。 三、为什么要有 any 设想一个场景,一个函数需要接受一个数组,数组内数据可以是任意类型,泛型不好解决这个问题,所以还得引入 any,而 unkown 是后来引入来代替 any 的。但在一般的强类型语言通常不具备那么多灵活性,比如数组只允许一种类型,那就可以通过泛型来解决。  JSON.parse 的类型声明也是 any,因为当初还没有 unkown,不然应该返回 unkown 更合理。 四、图灵完备的类型系统 TypeScript 为了不减弱 JavaScript 的灵活性,同时又能提供足够的类型约束,就带来了图灵完备的类型系统。 下面用类型来实现一个自动声明 N 个长度的定长数字数组,过程需要用到递归 ``` type ToArr<N, Arr extends number[] = []> = Arr['length'] extends N // 判断数组长度是否达到 ? Arr // 长度够则直接返回 : ToArr<N, [...Arr, number]>; // 长度不够则递归 type Arr1 = ToArr<3>; // [number, number, number] ``` 更进一步,甚至可以基于上面的 ToArr 再实现加法: ``` type Add<A extends number, B extends number> = [...ToArr<A>, ...ToArr<B>]['length']; type Res = Add<3, 4>; // 7 ``` 甚至有人用 ts 的类型系统实现了[象棋规则](https://zhuanlan.zhihu.com/p/426966480)。 五、readonly 和 as const 两者都可以将变量声明成仅可读,而 as const 是将类型转换成常量。下面再看看两者的一些细节。 ``` interface Foo { readonly a: { b: number, }, } const f: Foo = { a: { b: 1 }, }; f.a = { b: 2 }; // Error: 无法分配到 "a" ,因为它是只读属性 f.a.b = 2; // 这里则没问题 ``` 上面可以看出,readonly 只对当前对象有效,对其属性无效。但 readonly 对数组却能做到完全不可修改。 ``` const arr: readonly number[] = [2]; arr.push(1); // Error: 类型“readonly number[]”上不存在属性“push” ``` as const 把一个可变长度的数组声明变成一个固定长度的数组: ``` const args = [8, 5]; // number[] const func = (x: number, y: number) => {}; const angle = func(...args); // 这里会提示错误,因为ts不确定args是否有两个数 const args = [8, 5] as const; // 加上as const,将args转换成[number, number]即可 func(...args); // OK // 同时也不允许修改数组 args.push(2) // Error: 类型“readonly [8, 5]”上不存在属性“push” ``` 六、类型约束与控制流 在回调函数中已收窄的类型约束将被重置,因为该回调可能会在任何地方被调用,而里面通过闭包访问的变量有被更改的风险。 具体看下面例子: ``` function bar() { let v1: string | undefined = '123'; if (!v1) return; // 这里类型收束并未在返回的闭包中生效 return () => { v1.charAt(0); // error: 对象可能为“未定义” }; } ``` 如果要解决这个问题,tsc 就需要在编译时做作用域内的引用分析,这个不但会有性能隐患,也大大增加了 tsc 的复杂性。并且如果不使用 tsc,而是基于 babel 的 typescript 编译是不会进行 import 引用分析,编译时的上下文仅局限在当前文件。 所以对于控制流的条件约束,typescript 采用了悲观策略,即默认变量有可能被修改。 但这也会存在问题: ``` enum Result {Yes, No} let res = Result.Yes; function changeResult() { res = Result.No; } if (res === Result.Yes) { changeResult(); if (res === Result.No) { // Error: 此条件将始终返回 "false" // ... } } // 如果要解决上述错误,只需要将 res 替换为 getRes() function getRes() { return res; } ``` 七、协变和逆变 - 协变:子类型兼容父类型,即 Array<Father>.push(Son),这是可以成立的,因为 Son 是 Father的子类型,继承了所有 Father 的属性,所以对其兼容; - 逆变:父类型兼容子类型,与上面相反,具体看下面例子; ``` declare let animalFn: (x: Animal) => void; function walkdog(fn: (x: Dog) => void) {} walkdog(animalFn); // OK ``` 这里 animalFn 的参数声明需要的是 Dog,但实际传入的是 Animal,上面的本质就是 (x: Dog) => void = (x: Animal) => void ,所以参数是将 Animal 赋值给了 Dog,所以是 Animal 对 Dog 兼容,即逆变,如果将这个场景反过来,反而会出错。所以函数的参数是逆变,返回值是协变。 但 ts 的函数类型其实是双向协变的,但这并不安全,具体看下面例子: ``` declare let animalFn: (x: Animal) => void declare let dogFn: (x: Dog) => void animalFn = dogFn // OK,但这不安全 dogFn = animalFn // OK // 虽然在 ts 里像上面那样双向赋值(双向协变)是可以通过的,但这是不安全的 const animalSpeak = (fn: AnimalFn) => { fn(animal); }; animalSpeak((x: Dog) => { x.汪汪() // 这里运行会报错,因为传入的 Animal,不具备 dog.汪汪 方法 }); ``` 上面 animalSpeak 的调用,实际是将 Animal 作为参数赋值给了 Dog,这不满足函数参数逆变的原则,但在 ts 中却是可以通过编译的。 为什么 ts 允许函数双向协变:因为 ts 是结构化语言,如果 Array(Dog) 可以赋值给 Array(Animal),那么就意味着 Array(Dog).push 可以赋值给 Array(Animal).push ,从而导致设计上就允许了双向协变,这是 ts 设计者为了维持结构化类型兼容的一种取舍。但毕竟双向协变是不安全的,所以在 2.6 版本后,开启 strictFunctionTypes 模式,函数参数协变将会报错。关于双向协变具体可以看下面的例子: ``` typescript interface Animal { eat: '' } interface Dog extends Animal { wang: '' } let animalArr: Animal[] = []; const dogArr: Dog[] = []; animalArr = dogArr; // OK // Array<Animal>.push(Animal): number = Array<Dog>.push(Dog): number(参数协变) animalArr.push = dogArr.push; // OK ``` 参考: [](https://exploringjs.com/tackling-ts/toc.html)<https://exploringjs.com/tackling-ts/toc.html> [](https://www.zhihu.com/question/63751258)<https://www.zhihu.com/question/63751258> [](https://jkchao.github.io/typescript-book-chinese/tips/covarianceAndContravariance.html%E4%B8%80%E4%B8%AA%E6%9C%89%E8%B6%A3%E7%9A%84%E9%97%AE%E9%A2%98)<https://jkchao.github.io/typescript-book-chinese/tips/covarianceAndContravariance.html> [](https://zhuanlan.zhihu.com/p/143054881)<https://zhuanlan.zhihu.com/p/143054881> [](https://zhuanlan.zhihu.com/p/143789846)<https://zhuanlan.zhihu.com/p/143789846>
一、HEAD是什么? 在git中撤回操作,无论是reset、checkout和revert撤回上一步,都会用到HEAD这个指令字段,但这个HEAD到底指得是什么,一直没搞明白。其实一开始在学git原理的时候,都会看到下面这种图。  告诉你HEAD是一个指针,如果你用`cat .git/HEAD`这个命令查看HEAD,就会知道这里存储的是当前分支,如:`ref: refs/heads/master`。 但正如每个git入门教程里说的,这个`refs/heads/master`里存储其实就是当前commit的引用。这里可以理解为一个仓库就是一颗树,每个分支则是不同的树枝,树枝上有不同的节点(代表每一个commit),而commit之前也有父子关系,HEAD指针则是指向commit id,HEAD所在的commit就是目前本地仓库的状态。 那平时我们提交commit则是增加节点,同时HEAD指针后移,这个不必多说。但git的强大,不止如此,还可以通过reset、checkout、revert、merge和rebase等操作指令,花式移动指针,游走于整颗commit树,这个是这次笔记的重点。 二、merge和rebase merge是合并分支,rebase是整合分支(个人理解),是直接将分支信息整合进一个链条,这样的好处是看起来简洁。通常的操作是现在短期分支上rebase目标分支,然后在将短期分支merge进去。虽然rebase之后的分支看起来很整洁一贯,但正因为rebase强行将commit整合,就会出现下图这样提交时间先后不分的情况,git统一的处理是将合并进来的分支所有提交放在最前端;  当然,对于某些洁癖来说,rebase确实是个救星,就算是在`--no-ff`这种带分支信息的合并中,用了rebase,也能将一个分支的提交单独提出到一个分叉中,看起来比较直观,不会跟主分支里的提交混淆,不过如果说是一个健康的主分支一般也不会出现这种混淆的情况(分支内直接push),所以这里也就是提一提。 但实际上rebase的使用是有原则的,就是不要将私有分支的提交rebase到公共分支,因为这样会导致共有分支的提交记录改变(rebase的原理就是对比合并分支并将commit一一合并,从而用新的commit去覆盖),这样对其他协作者非常不利。可参考rebase的使用:https://cn.atlassian.com/git/tutorials/merging-vs-rebasingthe-golden-rule-of-rebasing 如果再带上`squash`命令,就可以直接把被合并分支中的所有commit合并成一个,提交记录就更简洁了,不过可能无法追溯细节提交记录,并且回滚也比较麻烦。 三、reset、checkout、revert 开发的时候,经常需要进行提交撤回的操作,一般用到这三个指令,他们的区别是: 1、reset只更改HEAD指针指向的commit id,如果这个操作撤回某些commit,则这些commit在log里会消失,并且这些commit引用会在git的垃圾回收处理过程中被删除,也就是这部分树枝之后会被锯掉; 2、checkout则为移动的目标指针单独建立一个分支,并移动HEAD,原分支不变; 3、revert新建一个commit,指针后移,并将目标commit的内容作为本次commit的内容,个人感觉这种操作更安全,毕竟会保留之前的记录;(但是要注意,如果你合并了某个分支,并且revert该分支中的一个commit,不要以为再合并一次这个分支就可以还原那个revert,是不行的,git会默认把这个revert导致的差异对冲掉,你如果想还原,要么reset或者revert那次revert) 下面是三种命令的使用场景总合,来源:https://cn.atlassian.com/git/tutorials/resetting-checking-out-and-reverting  四、~ 和 ^ 这两个符号在三中的操作中,经常会用到,个人理解为移动指针的单位。一中提到,commit之间存在父子关系,当commit是一条链没有分叉时,父子关系是递增下去的。如果是中间有合并操作,则上一次合并操作为父亲(暂时怎么理解,我了解的也不够深)。 所以从下面两张图可以看到,^n 符号是父亲节点中找第n-1个(因为^1就是当前节点),像这里^2则是到第一个父亲节点,^3是第二个,如果^4则会报错,因为不存在第三个父亲节点。 而 ~n 则是往上找到n-1层到第一个节点,~2则是找到父亲节点,~3则找到爷爷节点。  (c1是曾爷爷)   截图里的操作序列,还少了一个比较重要的点,就是`git reset HEAD~`命令会将HEAD移动到当前commit的第一个父亲节点(9b13a6c 合并),所以从上两个图可以看出,^和~的区别,但目前本人很少遇到用到这两个命令的场景,也暂不了解这两个命令有什么高级的用法,所以点到为止。 五、cherry-pick 这个命令也是一个很好用用的改变commit的指令,如这个指令名,它的作用就是将一个或多个commit捡出(pick),然后合并进当前分支。有点git merge some commit的意思。 六、git update-ref 命令用于更新一个指针文件中的Git对象ID。 在理解这个命令前,需要先了解一下git 的refs文件(http://www.chenchunyong.com/2017/01/06/git-refs-%E8%AF%A6%E8%A7%A3/) 我的理解是,git的refs文件,就是存储git下的各种管理分支的引用,同时远程分支和本地分支的追踪也是依靠这个文件。 我会去了解这个是因为遇到下面这个问题,git在创建新分支时,因为分支名为`hotfix/1129`,但由于前面refs的实现的原理,本地之前有一个hotfix分支,而这个hotfix分支在`.git/refs/heads/hotfix`这里标记了一个ref,而创建hotfix/1129时,则是想覆盖`.git/refs/heads/hotfix`这个文件为`.git/refs/heads/hotfix/1129`,这么做git自然不允许,所以报错 `refs/heads/hotfix exists`。  知道了原因后,解决方法有两个,一是使用` git update-ref -d refs/heads/hotfix`去删除hotfix的refs;二是直接删除hotfix这个分支,因为`refs/heads/hotfix`这里其实就是对hotfix分支的引用; 但个人觉得真正的原因就是这个命名导致的,因为出现了hotfix这种过于简单且不符合项目规范的命名,又没有及时删除导致的。因为这次错误是出现在测试人员那里,所以项目最好规范开发不允许取这种简单的分支名,或者不采用 / 符号来做分支划分,可以用 _ 等代替。 七、git revert 将一个操作撤回,并将这次撤回当作一个commit。这么做的好处有很多: - 这次撤回操作可追溯; - 相比直接reset,这个不需要强制push远程,因为这是增量操作。如果是reset,远程commit是多于本地的,这时候需要force push才能使远程同步,这个过程如果有人提交了远程就炸了; 如果是revert一次merge的话,需要带上-m %d 命令,表示你需要撤回的阶级,是这次merge还是merge中的某次commit,我的理解就是上面HEAD笔记里提到的父子commit概念;
摘要和非对称加密 在了解的安全协议之前,需要先讲两个前置概念,也是后续理解的关键。 摘要: 摘要算法是对数据的有损压缩,是单向不可逆的,就是一种哈希运算结果。可以用来做数据比较,当两份数据的摘要结果是一致的,说明两份数据也是一致的。常用的摘要算法:MD5、SHA-1等。 非对称加密: - 非对称加密,则有公钥、私钥之分,公钥可以公开,且加密解密只能是单向的,公钥加密私钥解密,或私钥加密公钥解密。 - 但由于公钥是公开的,所以私钥加密相当于所有人都可以解密,但这并不意味着私钥加密没有意义。当一个信息可以由公钥成功解密,就证明此消息必然是私钥持有者发出,这就能起到验证信息来源的作用,像一个签名。所以一般不叫私钥加密公钥解密,而是私钥签名公钥解签。 - 非对称加密需要复杂的运算,所以一般不会去加密数据本身,而是加密数据的摘要,然后接收方解密摘要后,再对收到数据进行校验,从而确定接受信息的可靠性。 - 常用的是 RSA 算法,它的密钥有 256/512/1024/2048/4096 等不同的长度。长度越长,密码强度越大,当然计算速度也越慢。 - 注:非对称加密是 HTTPS 实现安全传输的关键! 如何设计一个安全通信方案? 下面将会一步一步设计一个安全的通讯协议,每一个阶段会列出解决和遗留的问题。 1. 明文通讯 - 安全问题 1. 双方对称加密通讯,双方线下存储密钥 - 信息可以加密 - 随着通讯对象增加,需要存储的密钥会越来越多 - 每增加一个对象,都必须线下去交换一次密钥,非常麻烦 1. 非对称加密通讯,明文将公钥发出,双方交换公钥 - 公钥可以明文发送,不需要线下分配密钥,也不需要事先存好密钥 - 每次通讯都用非对称加密,计算量大 - 公钥对所有人开放,即意味着无法确定信息的准确来源,是谁发过来的 - 公钥交换过程是明文,可能会被中间人劫持修改(中间人在传输过程中修改成自己的公钥,即可监听对话) 1. 非对称加密传送密钥,然后再通过对称加密通讯。即生成一个密钥 A,通过公钥加密传输给对方,并告诉对方之后的通话要经过密钥 A 来加密。 - 解决非对称加密计算量大问题 - 仍无法确认信息来源 - 中间人劫持公钥 1. 到这里,如果不解决中间人劫持的问题,就无法进行下去了。所以我们需要引入一个可靠的第三者,我们称之为授信机构,机构生成一对非对称密钥,每个需要通讯的人都去此机构领取公钥,并且机构会对申请人的个人信息进行认证和签名(私钥加密)。此后,所有人通讯前,都用机构公钥去解密对方的机构签名,这样就能确认对方是谁了。所以此机构相当于是一个互联网的身份登记机构。 - 可以确认信息来源,同时杜绝了中间人劫持 由于存在授信机构,只需要申请一次公钥(证书),且只需要存储一个公钥,即可跟所有人进行加密通讯。而这个授信机构也就是现在的 CA机构(证书授权中心),机构签名和公钥则构成数字证书,每个浏览器都会内置 CA机构 的根证书。 下面会讲述数字证书和安全协议的更多细节。 数字证书 CA 机构(证书授权中心)会生成一个根证书(带有公钥)和私钥,根证书会内置在所有浏览器里,私钥则用于服务器证书的签名。所以只有经过机构认证的服务器,才能进行加密通信。 CA 机构向有资质的服务器发放服务器证书,不同安全等级的证书需要不同的申请资料,如申请电子商务服务器证书需要营业证明。 下图是证书的内容:(下面颁发者的签名只是个比喻,实际应该是一串加密字符) 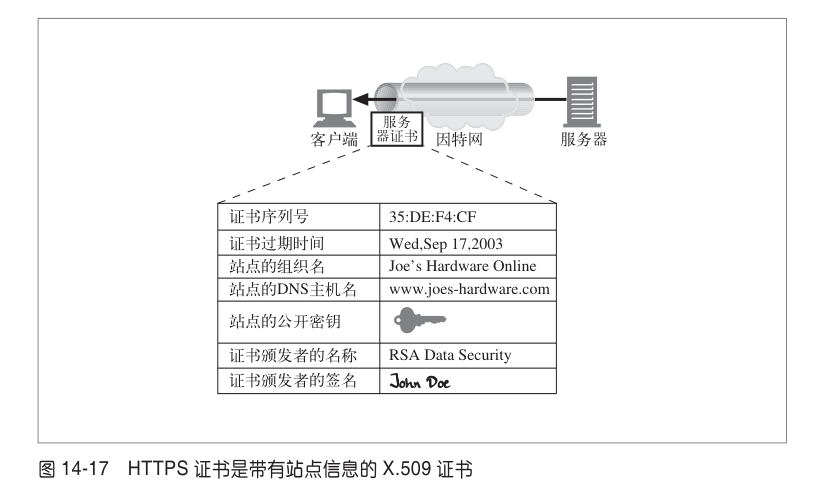 一个受根证书信任的证书 A,可以对另一个新建的证书 B 进行签名,这样根证书也会信任证书 B,这是一个证书信任链条。所以并非只有根证书才能给其他证书签名。 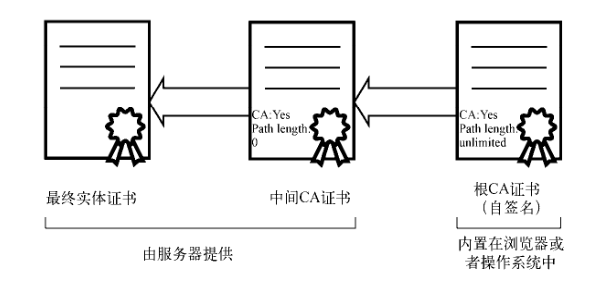 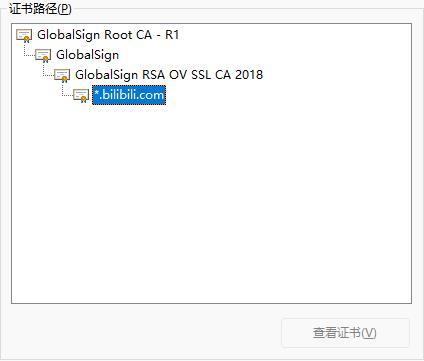 当客户端收到服务端的证书,会通过证书的发布机构(Issuer)递归向上反查到其根证书,从而保证证书信任链的有效。 SSL 和 TLS 安全协议 两者都是加密层的协议,TLS 是 SSL 的更新版本,修复了一些安全漏洞。因为两者很相似,所以下面以 SSL 为代表讲解安全层是如何建立的。  建立 SSL 连接 1. 客户端发送支持的安全协议、加密方法、随机数a(客户端生成)等; 1. 服务器返回确认的安全协议、加密方法,以及随机数b(服务端生成)和证书; 1. 客户端验证证书,首先查看证书的颁发机构、期限以及域名等,保证了证书本身信息合法后,通过根证书的公钥验明证书上的签名。验签后,取出证书公钥,对此次发送的信息进行加密。这次会发送给服务端随机数c(客户端生成),并通知服务端之后的通信将用密钥加密; 1. 服务端最后一次返回,通知客户端已知后续内容要加密,并且将之前发送内容生成hash值一并返回给客户端,以供客户端校验; 1. 通过前面几次握手,共产生随机数a、b、c,且同时存在于两端,两端用这三个随机数生成密钥,通过约定好的加密算法加密之后通讯的内容; 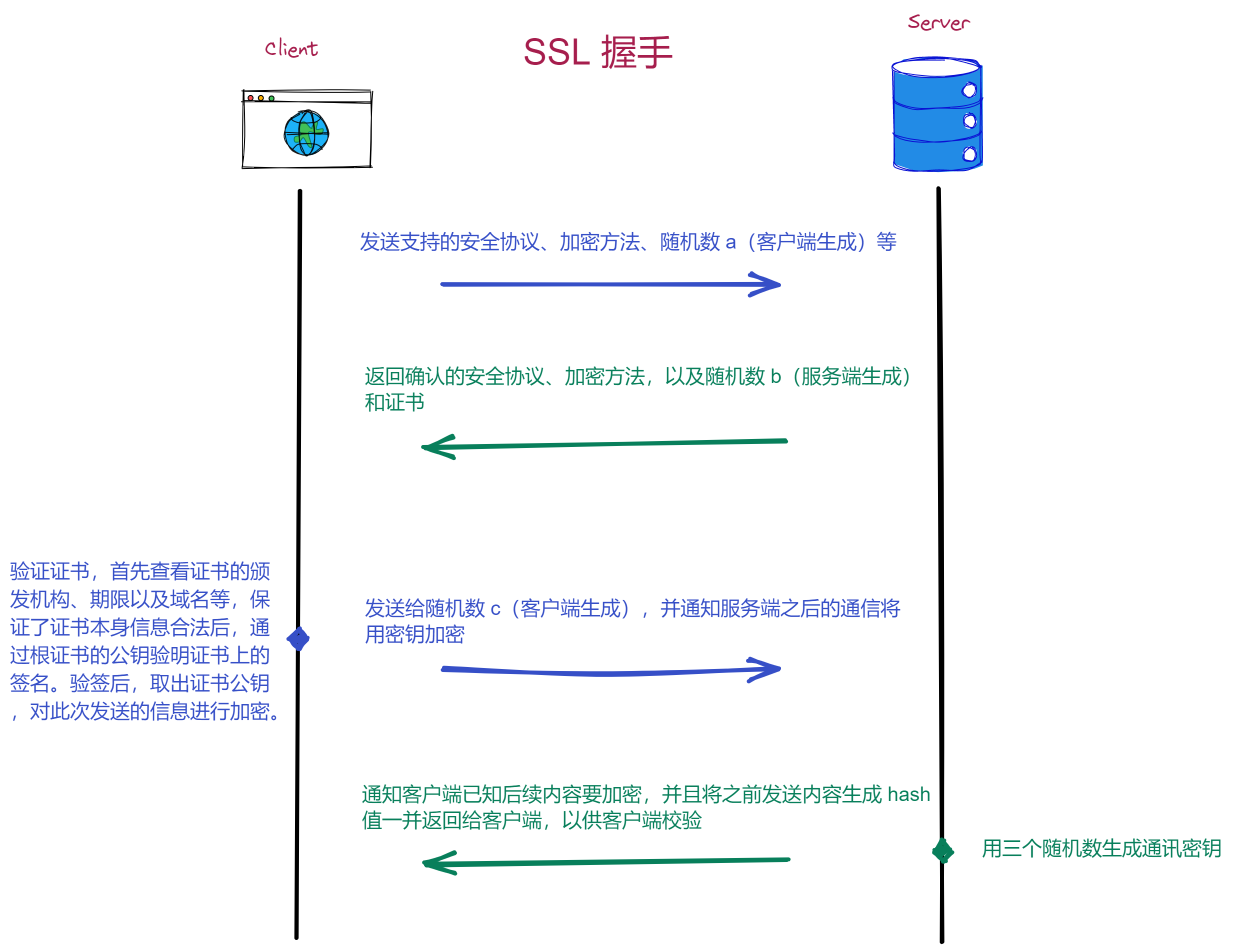 - 注:通过两端产生的三个随机数,能更好地保证密钥的随机性,其中 a、b 随机数是明文传输,只有 c 是通过服务器公钥加密传输的; 如何确定明文证书不会被劫持? 在证书生成的时候,除了有基本信息外,还有颁发机构的私钥签名,这个签名是通过对整个证书的内容(包括服务器公钥)摘要加密生成的。 所以如果有中间人想要调包证书,那浏览器会找不到解签的公钥而判定此证书是非法证书。 如果想把证书公钥换成中间人自己的,也不行,因为客户端也会对证书内容进行摘要,然后再跟证书解签出来的摘要进行对比,这样就能知道证书内容是否被修改过。 每次会话都需要握手吗? SSL 的多次握手需要一定时间,所以当连接断开一段时间内,双端都会保留一个 Session Id 用于快速重新握手。当重连时,客户端依然进行第一次握手,但会带上之前连接保留下来的 Session Id;服务端在上此连接时,将 Session Id 作为 key,密钥作为 value 存储起来,拿到客户端发来的 Session Id 就可以验证是否存在过,存在则告知客户端恢复连接。 但 Session Id 存在两个问题,一是服务端存储大量的 Session Id 和通信密钥,内存占用高;二是如果服务器是集群,则需要一个共享数据库去存储 Session Id,增加读写性能压力。 为了解决这两个问题,后来协议新增了一个 Session Ticket。顾名思义,它是服务端给客户端发送的一个票据,通过这个票据可以恢复会话,不再需要存储于客户端。具体操作是,当完成完整握手后,服务端会将此次的通讯密钥加密成 Ticket 发送给客户端(Ticket 只有服务器能解密),并且还需要告知客户端 Ticket 的时效,到时必须删除。当客户端之后重连时,将 Ticket 带给服务端,服务端解密出上次的通讯密钥,即可恢复加密通信。 https 代理 在写这篇文章的同时,我实现了一个简单的代理抓包工具,感兴趣的可以看下 https://github.com/Mess663/v-proxy 参考: [](https://imququ.com/post/web-proxy.html)<https://imququ.com/post/web-proxy.html> [](https://awesome-programming-books.github.io/http/HTTP%E6%9D%83%E5%A8%81%E6%8C%87%E5%8D%97.pdf)[https://awesome-programming-books.github.io/http/HTTP权威指南.pdf](https://awesome-programming-books.github.io/http/HTTP%E6%9D%83%E5%A8%81%E6%8C%87%E5%8D%97.pdf) [](https://github.com/anzhihe/Free-Web-Books/blob/master/book/HTTPS%E6%9D%83%E5%A8%81%E6%8C%87%E5%8D%97.pdf)[https://github.com/anzhihe/Free-Web-Books/blob/master/book/HTTPS权威指南.pdf](https://github.com/anzhihe/Free-Web-Books/blob/master/book/HTTPS%E6%9D%83%E5%A8%81%E6%8C%87%E5%8D%97.pdf) h[ttps://www.lyyyuna.com/2018/03/16/http-proxy-https/](https://www.lyyyuna.com/2018/03/16/http-proxy-https/) [](https://www.ruanyifeng.com/blog/2014/02/ssl_tls.html)<https://www.ruanyifeng.com/blog/2014/02/ssl_tls.html> [](https://www.bookstack.cn/read/https-mitm-proxy-handbook/doc-Chapter3.md)<https://www.bookstack.cn/read/https-mitm-proxy-handbook/doc-Chapter3.md> [](https://segmentfault.com/a/1190000024523772)<https://segmentfault.com/a/1190000024523772>
> 在使用一段时间的hook后,可以说hook对开发体验有很大的改进,解决了以前的痛点。 优点 1. 生命周期化作钩子,可以在函数组件内自由使用,逻辑聚合、复用方便; 2. 自定义hook代替高阶组件,更优雅简洁; 3. 不用声明繁杂的类组件,不需要this,可以简化一些代码; > 但是hook的出现也有一些争议,hook的改进并非完美无缺的,还需要社区去探索一个最佳实践。 缺点: 1. 会增加一定心智负担,因为使用useEffect不像以前的生命周期那么直观,需要考虑到依赖的影响,还需要考虑跨渲染次数的数据存储,如果使用不当或者没有做好缓存会经常出现频繁渲染的问题; 2. 因为太灵活,所以团队合作如果大家对hook的熟悉程度不同,写出来的代码上下限会更大; class转变为函数 我觉得React在一开始使用类来声明组件,一方面是这个很直观,当你想到状态、方法和渲染函数的集合时,第一反应会是用一个类来承载,另一方面是这也让使用者更好上手,API比较直观容易理解。 类组件的主体是这个类,渲染函数只是其中一部分,但其实并不是每个组件都需要一个复杂的实例,真正的主体应该是那个组件不可或缺的渲染函数,所以其实将一个渲染函数作为一个组件主体才是正确的做法。 于是从类组件到函数组件,只需要将类中的上下文抽离出来,将render函数作为主体,通过钩子的方式为函数组件提供生命周期的访问能力。 为什么是这些hook 以前一般我们不会在render函数里放任何副作用代码,因为我们知道render函数会经常重复执行。所以需要引入useEffect来解决这个问题,通过闭包的方式记录下副作用代码,并在DOM渲染完成后执行它。再通过声明依赖的方式去告诉React何时更新并执行这个闭包,很好地代替了mount和update生命周期。 所以一个useEffect实际上是要告诉React,一个函数需要依赖什么状态,并在渲染后执行这个函数。 但光有useEffect和useState还是不够的,函数组件会在每一次渲染重新执行,意味着我们还需要一个能在多次渲染中存储数据的能力,这是用来代替原来class this的部分功能,它就是useRef。至于useMemo和useCallback都是基于useRef的实现,主要起到通过缓存减少渲染次数的作用。 而useReducer则更多的是对状态管理的补充,useState使得状态声明分散,粒度控制比较头疼,加入useReducer,可以将同类型的状态优雅的归类在一起。其他hook都只是一些能力补充,而自定义hook则增强了逻辑的分层和抽象能力,让react hook真正的健壮起来。 有一点需要注意的是,因为hook脱离渲染函数,所以他是怎么确定每个hook的引用呢?答案是首先通过use前缀的约定标记hook,再根据调用顺序来维护引用,每当调用了hook,则把之前存储好的对应顺序位置的引用拿出来即可,这也是为什么hook不允许被条件判断包裹的原因,这会导致hook调用顺序不一致。 增加的这些API确实是给了另一种思维方式,现在整个函数有的只是每一次渲染,所有的hook都是围绕着每一次渲染去执行的。 > 对React的理解尚浅,有错误之处,请务必指出,谢谢!
1、选择排序 时间复杂度:O(n^2) 原理:通过两层循环来实现,外层遍历整个数组,内层再遍历一次数组并找到未排序数组中的最小数组(通过迭代比较,不停去相对最小值),然后将最小值与第一个数组项对调,接着外循环进入第二轮,便从第二项数组开始重复上述操作,直到整个数组排列完毕;  2、插入排序 时间复杂度:O(n^2) 原理:依然要通过两层循环,外循环便利每个数组项,内循环从外循环的数组项(i)开始往前遍历,如果当前数组项比前一个小,则与前一个调换位置,这样一直循环重复,数组就逐渐归位了; 其实本质上跟选择排序一样,通过两个循环来排序,插入排序虽然在内循环次数上一般会比选择排序边际递减地快,但也付出了大量的数组转换的操作;(代码下图①) 理论上来说插入和选择两种排序实际效率应该相近,但事实并非如此,在随机的数据表现上,插入排序是明显慢于选择排序,这主要是因为插入排序中大量的数组项值调换赋值的操作; 所以接下来要改进插入排序,减少数组项调换复制操作,替代为单向复制,在内循环中不再是比前一位小就调换,而是先将 j(当前项) 的值取出,将 j-1 的值复制进目前的 j 项中,先不改变 j-1 的值,然后再拿当前项去跟 j-2 比,如果当前项还是更小,则重复之前操作,直到正确位置,再将当前项的值复制进去,这样就成功减少了近一半的赋值操作了;(代码下图②) 事实证明,优化过的插入排序,在十万随机数据级别已经领先排序一半了,更何况插入排序在找到正确位置后就会停止循环,对随机性较低的数据则有更大优势;(如下图)  插入和选择的性能比较^  ①改进前 ^  ②改进后 ^ 3、冒泡排序 时间复杂度:O(n^2) 冒泡排序依然是两层循环,跟选择和插入排序思路差不多,就是外循环遍历,内循环不断向后比较调换,两层循环结束后结果就排序好,这里就不再去实现了,都一个调性。 4、希尔排序 时间复杂度:最坏还是O(n^2) 原理:希尔排序将插入排序作为它的子进程,它的核心是一个叫步长(gap)的概念,这个步长可以理解为一个类似疏密程度的概念。它共有3层循环,外层是以步长为循环,一般取数组的一半,循环一次再除一半,中层和里层就是插入排序的操作,不过不是跟前一项比,是跟当前索引减去步长后的那一项比。说到这里就可以理解为什么我说步长是类似疏密程度的概念,当步长不断除于2,变得越来越小,直到零停止循环,这个过程中,插入排序的比较项间越来越近,逐渐数组被排列出来。 其实也是利用插入排序在数据随机性较低情况下很高校这个特点,随着步长降低,整个排序循环越来越高效。  通过比较,在10W级的随机数据下,它的速度比前面的排序方法快的不是一点点,看下图。  更直观的,可以看下图,来自维基百科;  5、归并算法 时间复杂度:最坏还是O(nlogn); 原理:归并算法可以分为两部分,第一部分就是将一个数组两两分开,递归进行,直到分到只剩下1个,这时候进行第二部分,也就是核心部分,将每个单独项与邻近项再两两归并,并且在归并后进行一个排序,最后不停往回归并,直到归并成一个有序的数组; 那么这个归并后的排序怎么进行呢?我们知道,归并前有两个相邻数组,他们之间之前没有联系过,那怎么保证他们归并后是排好序的呢?首先将这两个要合并的数组成为arr1,然后再将这两个组数组复制一份成为arr2(再将arr1的两个数组合并),然后将arr2中两个数组从头开始依次以擂台的形式互比,谁小谁就先被赋值回arr1较前的位置,arr1从头往后按顺序赋值下去,直到排号序。最后通过这样递归的方式将整个数组排好序。我这里用了很多次“合并数组”这个词,但实际代码里为了性能更好,一般不会这样频繁操作数组,而是将数组的序号抽象出来,达到分开和归并的效果,具体代码看下图;  6、快速排序 时间复杂度:在某些最坏的情况下复杂度为O(n^2),如果是完全随机就是O(nlogn); 原理:快速排序也是运用了分组递归的思想,首先找到这个分组的分界点(一般为当前数组首位),然后将这个分界点在数组中进行循环比较,最后让它回到它正确的位置,以此分界,分为两个数组递归下去,在这样的过程中逐渐完成排序。代码如下图。 这里有一个很重要的一步是,在分界点进行循环比较时,需要将比它小的数往前移,就是下图for循环里的数组对调。  在原理中,我提到,分界点一般取首位,但如果遇到近乎有序的数据时,就会出现O(n^2)的时间复杂度,要优化这一点,很简单,只要分界点去随机位就行,这样出现最坏情况的可能性虽然仍然会存在,但极低了,如下图;  还有一种情况就是如果数据中存在大量重复,也会导致递归分组下去会出现像上面那样分组极端不平衡的情况,最终时间复杂度会出现最坏的情况。为了解决这种情况,需要进行双向遍历,这次循环比较分界点分别从头尾两个方向同时进行,小等于分界点和大于等于分界点的被分别纳入两个分组,这样就能一定程度上将重复的数据分开。具体实现看下图,只改动了mid的取值,所以单独写了一个函数来取值; 
我们公司的微信小程序代码由于迭代了比较久,应用了很多微信小程序的新特性以及使用webpack,所以用头条的搬家工具转换之后,仍然不能直接运行。主要面临两个问题:1、头条小程序不支持分包,采用流加载;2、头条不支持wxs,并且没有替代品。 为了解决第一个问题我魔改了一位大佬开源的百度小程序搬家工具(头条的搬家工具没开源)。地址:[v-wx2toutiao](https://github.com/Mess663/v-wx2toutiao) 这个工具主要做了下面4件事: - 利用头条搬家工具转换api和模版等差异; - 将分包加入进主包(修改文件位置和app.json); - 将ttml、ttss、js、json所涉及到的所有依赖路径进行调整; - 因为头条小程序ttml中使用include引入模版不会继承作用域,所以将inlude的源代码替换进来; 至于第2个wxs的问题我暂时没有想到比较好的解决方法,只能手动去修改成js。改好这两个问题,基本可以初步跑通。 ---- 还有一些其他小坑,在这里提醒一下: - 没有nextTick,建议用setTimeout代替 - ios 不支持真机调试 - 父元素 catchtouchmove 触发会导致子元素 scroll-view 无法滚动 - [ios] textarea 用在 hidden 判断隐藏,真机显示后不能输入文字 - 组件内不可声明 pageLifetimes - component 没有 observe - [iphoneX] 部分有 padding 的 view 会出现溢出,设置 box-sizing: border-box 即可解决,就算全局给 view 标签选择器加 box-sizing: border-box 也没用,必须加在类选择器下。 - [android] 设置自定义导航栏,导航栏标题依然会出现 - [ios] tt.chooseImage 选择图片,不知道出于什么目的,自动会将图片格式转为 jpeg 格式,并且在临时链接加上一些参数后缀,导致我上传七牛失败 - 开发者工具在不同系统里的表现不一样,我遇到都是 mac,同版本的开发者工具,结果对 css !import 的支持却是不一样的。 还想吐槽一下,头条小程序的社区实在是太不用心了,很多开发者的提问连回复都没有。遇到问题,一搜大家都有遇到,就是没有官方回应,心态崩了。
一、适配方案的利弊 缩放 最早是直接用 px 来写,然后用 meta 标签里的 scale 来缩放整个页面,简单粗暴。好处是简单快速,坏处是不能控制部分样式的缩放,一些边框之类的在小屏会变得很细。据说早期天猫首页就是这么干的。其实之后所有适配方案都是这个原理,在编码的时候以设计稿为标准,到手机显示时则根据不同机型的显示宽度而缩放,只是缩放的技术不同。 rem - 1rem 等于 html 的 fontSize 大小; - rem 适配方案只需要给 html 的 fontSize 设置任意大小。因为设计稿一般为 750px 宽,所以 fontSize 设置为 75px 是比较常见的经验标准,太大或太小对最终结果的精准度可能有影响。之后就可以确定 1rem = 75px,然后在还原设计稿时将 px 计算转成 rem 即可。并且要在 JavaScript 中加入脚本([flexable.js](https://github.com/amfe/lib-flexible)),根据屏幕显示宽度来动态改变 html 的 fontSize,屏幕宽度越大则 fontSize 越大; - rem 的优势是根节点 fontSize 可控(即 rem 的缩放标准完全可控),兼容性好。但始终是为了模拟出 vw 的效果,存在多一层转换,麻烦、不直观且精准度稍差; vw - 1vw 等于当前屏幕显示区域的百分之一; - vw 就是为动态布局而生的,所以不需要辅助任何脚本。一般设计稿宽度为 750px,那么还原设计稿的时候,1vw = 7.5px,根据这个将设计稿上的 px 换算成 vw 即可; - vw优势是精确、便捷,但兼容性稍差,标准的实现比 rem 晚 3 年; em - em现在一般不用来做移动端适配,这里只是顺带一讲; - em 是唯一一个可以在局部实现相对长度的单位; > em 在 font-size 中使用是相对于父元素的字体大小,在其他属性中使用是相对于自身的字体大小,如 width(来自:MDN) - em的出现是为了解决文字无法跟着页面一起放大这个问题。在ie6的那个年代,若使用px来设置 font-size ,当用户使用 Ctrl+滚轮 来放大页面时,文字是不会跟着放大的。但是现代的浏览器已经没有这个问题了; - 利用 em 根据自身字体动态适配的特性,可以实现很多需求,如根据字体大小动态改变行高、宽度、边距等; 二、逻辑像素和物理像素 逻辑像素就是我们平时所讲的像素,也就是 CSS 中的 px ,所以逻辑像素是一种抽象化的数字单位。而物理像素是指电子屏幕的最小发光单元。 其实最早的时候,不需要这样严格区分,因为那时候 1 逻辑像素就是用 1 物理像素来显示,也就是设配像素比(DPR,物理像素和逻辑像素的比例)为 1。后来 iphone4 打破了这个规则,它那块视网膜屏幕可以用 2 倍物理像素来显示 1 逻辑像素,从而使手机的显示效果更细腻。如下图,即 DPR2 ⇒ 横纵各有 2 个像素。 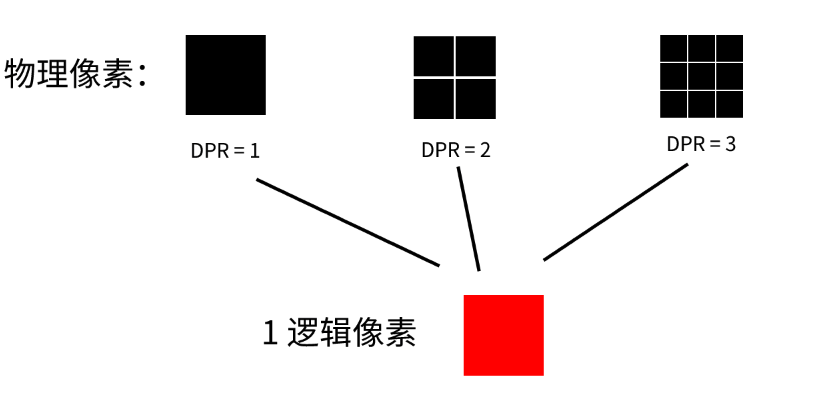 > 手机还有屏幕像素密度(PPI as Pixels Per Inch)的概念,也就是每英寸所包含的物理像素数量,一般来说在手机的使用视距下 PPI 达到 300 人眼就无法看出屏幕的像素点,这也就是苹果的视网膜屏幕的名称来由。 三、移动端图片模糊 移动端适配图片,由于移动端 dpr 不同,导致相同的位图会在高 dpr 的手机上模糊,需根据 dpr 使用N倍图可解决,即 dpr = 2 使用 2 倍图。 原因是,位图的像素信息(位置、颜色)是固定的,但在高 dpr 的屏幕显示时,会用数倍的物理像素去显示同样的逻辑像素,底层的算法并不会将物理像素一一对应上图片像素,而是进行就近取色,最终导致图片模糊。如下图: 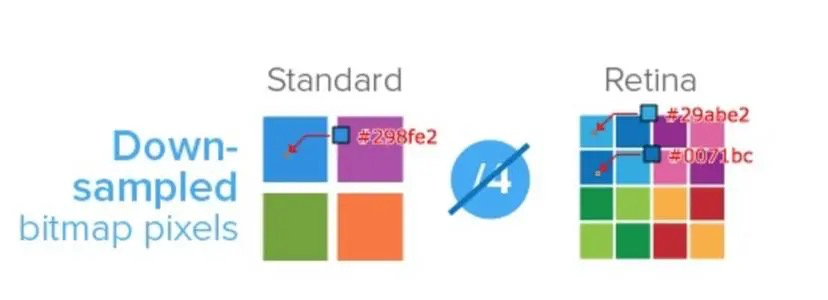 为什么要就近取色,而不是直接通过多个物理像素显示同一颜色呢?是因为用数倍物理像素显示一张图片时,如果只是简单粗暴的用 N 个物理像素直接显示 1 个图片像素,在移动端的高素质屏幕下锯齿感会很明显,为了解决这个问题则采用了平滑处理技术(就近取色属于其中一个操作)。假设有一张显示 0 的图片,则下面是处理过程: 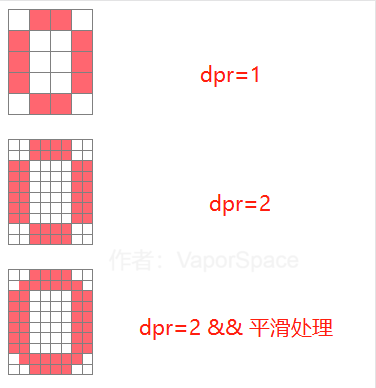 从上图可以看出,dpr2 在图像的细腻程度上能比 dpr1 处理得更好,所以才不是简单地用 4 个物理像素代替 1 个物理像素。最终结论是不是不能直接取色,而是就近取色更好。 四、小数像素导致的图片比例失调 做移动端适配的时候因为 px 是由 rem/vw 转换后的值,所以肯定会存在小数的情况,小数逻辑像素无法与物理像素完美对齐的,不可能让 1 个完整的物理像素去显示 0.333 的逻辑像素,所以面对这种情况webkit内核会有两种对齐方案: 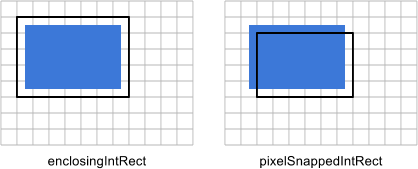 蓝色代表计算尺寸,黑线框代码实际对齐后的尺寸。图片来自:[](https://trac.webkit.org/wiki/LayoutUnit)<https://trac.webkit.org/wiki/LayoutUnit> enclosingIntRect 是简单地将渲染面积扩大 1px,保证能完全覆盖渲染的物理像素,这个方案只在少部分地方用到,如渲染svg,为了保证盒子能完整包裹矢量图。 pixelSnappedIntRect 则顾名思义,是指在容器内折断像素的方案。但并不是简单的四舍五入,因为如果仅仅四舍五入,会导致最终撑开或与容器相差太大,这个方案是为了保证最终渲染结果跟计算结果至多相差 1px。一个容器内有三张宽 14.25px 的图片真正的大致渲染计算过程是: - 首先将容器第一张图宽度四舍五入,那么第一个张图变成 14px 宽; - 因为第一张图四舍五入后少了 0.25px ,那第二张图则需要相应加上 0.25px,14.25 + 0.25 = 14.5px,四舍五入后则为 15px; - 第二张图多用了 15 - 14.5 = 0.5px,所以第三张图要减去这 0.5px,14.5 - 0.5 四舍五入后为 14px; - 最终,容器都计算宽度为 14.25 3 = 42.75,实际对齐物理像素后是14 +15 +14 = 43,这跟我们声明的宽度仅误差了 0.25px,所以最终渲染结果与小数像素的误差不超过 1px。   从上面的计算结果来看三个 div 中第二个的宽度是不同的,所以这也就是小数像素导致样式偏差的原因。因为这种样式偏差在各种布局盒子里都会存在,但因为在图片上效果更明显(图片挤压),所以通常只在图片显示时需要处理这个问题。目前没有比较好的解决方案,只能尽量写死像素,图片则可以使用 svg。 这一块是关于 [LayoutUint](https://trac.webkit.org/wiki/LayoutUnit) 的知识,是用来解决页面缩放时的渲染问题的,具体可以查看 [webkit 团队的文章](https://trac.webkit.org/wiki/LayoutUnit) 五、移动端适配方案的思考(来源:[](https://www.zhihu.com/question/21504656)<https://www.zhihu.com/question/21504656>): - 在嵌入进客户端时,会出现不同尺寸手机的web适配和native适配不一致,导致用户体验割裂; - 在设计层面,当客户使用更大屏幕期望地是能看到更多的内容,而这个适配方案却仅仅是让5寸屏幕和4寸屏幕到的信息量是一样的; - 关于字体的问题,从用户体验来说用户希望看到的字体是绝对大小的,就像看报纸,多大张的报纸,字体都应该是一样大,有一个最适合阅读的字体大小,而自适应打破了这种设计哲学。[知乎](https://www.zhihu.com/)的移动端页面,则完全使用了 px; 参考资料:\ [CSS的值与单位](https://developer.mozilla.org/zh-CN/docs/Learn/CSS/Building_blocks/Values_and_units)\ [LayoutUnit & Subpixel Layout](https://segmentfault.com/a/1190000021624120)\ [rem 产生的小数像素问题](https://fed.taobao.org/blog/2015/11/05/mobile-rem-problem/)\ [LayoutUnit](https://trac.webkit.org/wiki/LayoutUnit)\ [深入了解canvas在移动端绘制模糊的问题](https://juejin.cn/post/6844903828916011022)
函数式编程 命令式和声明式 我们入门编程的时候,通常都是从命令式编程开始,即最简单的过程式代码。后来为了处理大型项目又接触到面向对象,也属于命令式。而函数式编程属于声明式,其实它的出现早于面向对象。 MySQL就是一个很好的声明式语言的例子,它仅仅是声明了流程,却没有将过程的细节暴露出来。 ``` MYSQL SELECT from data_base WHERE author='jack'; ``` 再举一个例子来比较命令式和声明式的代码: ``` JavaScript const arr = [1, 2, 3, 4, 5] // 要求将上面的数组中小于 3 的去掉,并且将剩下的数乘上 2 // 命令式 const result = [] for (let i=0; i<arr.length; i++) { if (arr[i] >= 3){ result.push(arr[i] 2) } } // 声明式 const result = arr.filter(n >= 3).map(n => n2) ``` 看了上面的例子你可能会想,声明式的代码就这?再看看上面的 MySQL 的例子,声明式确是如此,通过 filter、map 等方法,封装了细节,然后将逻辑声明出来,并不需要一步一个命令地说明要怎么做,所以更简洁,而这就是最基本的声明式代码。 当我们学面向对象的时候,都会先知道它的三个特性:封装、继承、多态。基于这三个特性,人们在编写代码会延申出很多最佳实践,即设计模式,如工厂模式、依赖注入等。而函数式编程也是如此,有对应的特性和最佳实践。  函数式 函数式编程是以函数为主的编程风格,其实程序就是由一段段逻辑组成,而将这些逻辑分割成一个个函数,再将其组合发挥到极致。 函数式解决了一个问题,当命令式的风格写代码时,一开始你可以很直接的完成任务代码,但当你开始考虑边界处理和代码复用,渐渐的,你的代码会逐渐背负它本不该有的复杂度,而函数式编程能解决这个问题。 程序的本质,除了是数据结构和算法,还可以是计算和副作用。 ``` JavaScript // 先看个例子,从 localStorage 中取出所有用户数据,并找出年龄最大的,显示在 DOM 上 const users = localStorage.getItem('users') const sortedUsers = JSON.parse(users).sort((a, b) => b.age - a.age) const oldestUser = sortedUsers[0] document.querySelector('user').innerText = oldestUser.name ``` 上面的代码很平常,但是理解起来却需要一定时间,先做个函数式的优化,将上面所有步骤封装一下。 ``` JavaScript const getLocalStorage = (key) => localStorage.getItem(key); const getSortedUser = users => users.sort((a, b) => b.age - a.age) const first = arr => arr[0] const writeDom = selector = text => document.querySelector(selector).innerText = text; const prop = key = obj => obj[key] writeDom('user')(prop('name')(first(getSortedUser(JSON.parse(getLocalStorage('user')))))) ``` 我知道上面的代码看起来比较奇怪,一是最终调用逻辑需要从右向左看,二是 writeDom、prop 这样分多次将参数传入,即柯里化。尽管它看起来奇怪,逻辑上确实比之前更清晰易读,并且所有函数都灵活、易扩展。 这就是函数式代码,强调声明式的代码以及函数的灵活组合。函数式编程的目标是使用函数来抽象作用在数据之上的控制流与操作,从而在系统中消除副作用并减少对状态的改变。后面会更加详细地阐述这点。 下面对代码进一步优化。 柯里化 柯里化即把一次传入多参数的函数,转换成能分次传入参数的函数。但是现在我们需要讨论一个参数先后顺序的问题,比如对 Array.map 进行柯里化封装,不同的参数顺序会导致不同的效果: ``` JavaScript const listMap = fn => list => list.map(fn) const allAddOne = listMap((o) => o + 1) allAddOne([1, 2]) // [2, 3] // 如果反过来会是下面这样 const listMap2 = list => fn => list.map(fn) const mapList = listMap2([1, 2]) mapList(o => o + 2) // [2, 3] ``` 前者先传 fn 再传 list 更符合函数式的规则,因为函数式是针对逻辑的组合,而不是针对数据的组合。这也解答了为什么前面的例子需要把部分函数柯里化,这样更方便组合。 优化代码——函子(functor) 其实我以前就写过如下的声明式代码: ``` JavaScript // [1, 2] => [1, 2, 3] => [2, 3] => [6, 9] [1, 2] .concat([3]) .filter(x => x > 1) .map(x => x 3) ``` 我以前写的时候就觉得这种链式调用的写法非常的清晰,要是所有逻辑都可以这么写就好了,而函数式编程就是这么个思路。如果我们要处理非数组时,其实我们可以用一个数组将其包裹,如 ``` JavaScript // [' 123 '] => ['123'] => [123] = [124] ⇒ 124 [' 123 '] .map(o => o.trim()) .map(o => Number(o)) .map(o => o + 1) .pop() // 124 ``` 但是上面这么做并不优雅,每次都要包裹在数组里。所以我们可以创建一个包含 map 方法的对象,从而实现链式调用: ``` JavaScript const Box = (v) => { return { map(fn) { // 将数据放进盒子 return Box(fn(v)) }, getValue() { // 从盒子中取出数据 return v } } } // 重写上面的例子 Box(' 123 ') .map(o => o.trim()) .map(o => Number(o)) .map(o => o + 1) .getValue() // 124 // 重写前面的例子 Box(getLocalStorage('user')) .map(JOSN.parse) .map((o) => o.sort((a, b) => b.age - a.age)) .map(first) .map(prop('name')) .map(writeDom('user')) // 比起之前的一长串,这样看起来清爽多了 ``` 而这个带 map 方法的 Box 在函数式编程中称为函子(functor),即一个包裹着数据的容器,它提供链接数据操作的能力。 进一步实践——Maybe 但上面的例子还有个问题,就是 getLocalStorage 不一定会返回有效数据,也可能是 undefined,这样会导致后续报错。所以,最好就是在遇到目标不存在的情况时,能跳过接下来的所有操作。 函数式的思路是,我们写两个 Box,一个叫 Just ,他会正常处理所有流程,另一个叫 Nothing ,它会自动跳过所有的流程,只需要在一开始判断用哪一个 Box 即可。 ``` JavaScript // 有值 const Just = (val) => ({ map: (f) => Just(f(val)), getValue: () => val, isJust: () => true }) // 无值 const Nothing = () => ({ map: (f) => Nothing(), // Nothing 不会执行后续的所有操作 getValue: (defaultVal) => defaultVal, isJust: () => false }) // 再用一个 Maybe 来判断使用两个特殊的 Box 中的哪一个 const Maybe = (val) => val === null || val === undefined ? Nothing() : Just(val) // 用 Maybe 重写前面的例子 Maybe(getLocalStorage('user')) .map(JOSN.parse) .map((o) => o.sort((a, b) => b.age - a.age)) .map(first) .map(prop('name')) .map(writeDom('user')) ``` 上面的Maybe 也叫做 Monad ,是基于函子(Box)所实现的,可以理解为 Monad 是专门处理某些场景的函子,类似的 Monad 还有很多,用于处理函数式下遇到的各种场景。后面还会介绍另一个常见的 Monad。 纯函数和副作用 其实 React 中每一个渲染函数都是一个纯函数,相当于 UI = Funtion(state)。所以每次修改 state 后,React 的会重新跑一边渲染函数,只要传入一样参数,无论调用多少次,渲染出来的 UI 都是一致的,这就是纯函数。 纯函数有什么优点呢?1、无副作用,可任意放置,不影响上下文,易于组合;2、易于维护和重构,只要输入输出一致,随便改都不会影响外部;3、输出稳定,易于单元测试;4、输入和输出完全对应,便于缓存,只需判断输入是否更改就行。 但是纯函数的另一面就是副作用,因为现在的程序在运行中必然需要做 IO 操作(请求、操作DOM等),这些就是所谓的副作用,如果一个函数包含了副作用,那么就无法做到多次调用结果一致,指不定哪一次内部的变量就被副作用修改了。 而 React 处理副作用的方式是使用 useEfffect,来将副作用收集起来,虽然无法将副作用完全去除,但可以收集起来统一管控。这也是为什么 useEffect 内的函数并非在执行渲染函数过程中就执行,而是维护成队列,在渲染完后再执行,就是为了统一处理副作用,保持渲染函数的纯净。 那么在一般的函数式编程中,如何处理副作用呢? 副作用——IO Monad 跟 React 的思路一样,集中处理。将副作用包裹在函子中,并添加一个 runIO 方法,这样有个好处,就是在最终 runIO 方法调用时才执行,这样就能很安全地拿捏副作用了。 ``` JavaScript const IO = (fn) => { return { map(fn) { return IO(() => fn(sideEffectFn())) // 让所有副作用延迟执行 }, runIO() { // 显示调用 IO ,使得我们可以将 IO 操作更明显地放在一起,方便管理 fn() }, } } // 例子: const getNumDom = () => document.querySelector('num') const writeNum = (text) => { document.querySelector('num').innerText = tex } const ioEffect = Maybe(getLocalStorage('user')) .map(JOSN.parse) .map((o) => o.sort((a, b) => b.age - a.age)) .map(first) .map(prop('name')) .map(o => IO(() => writeDom('user')(o))) ioEffect.getValue().runIO() // 一次运行副作用 ``` 这样除了可以集中把控副作用外,还可以将读数据、处理数据、写数据很清晰的分离,并且更利于阅读和维护 但上面返回的是 Maybe(IO(o)),Monad 出现了嵌套,导致最终调用冗余: ioEffect.getValue().runIO() 。这时候我们只需要给 Maybe 加一个 foldMap 方法即可,这个方法目的是在传入下一个 Monad 时接触嵌套。 ``` JavaScript ... foldMap(monad) { return monad(val) } ... // 重写上面嵌套的例子 const ioEffect = Maybe(getLocalStorage('user')) .map(JOSN.parse) .map((o) => o.sort((a, b) => b.age - a.age)) .map(first) .map(prop('name')) .foldMap(o => IO(() => writeDom('user')(o))) ioEffect.runIO() ``` 通过 foldMap 可以解决 Monad 嵌套的问题,所以 foldMap 就是 Monad 必须的一个方法。 组合函数,让数据的流动更简洁 Box.map(fn).map(fn) 虽然看起来很清晰,但其实还有一种写法能组合函数,就是写一个方法将所有函数组合起来,省去 map,看起来更简洁。尝试写一下这个方法,就叫它 pipe ,像水管一样组合函数: ``` JavaScript const pipe = (...fns) => (arg) => fns.reduce((lastVal, fn) => fn(lastVal), arg) ``` 为了能将 Monad 也放进 pipe 中,我们需要再封装一下 map 和 foldMap 这两个必要的方法: ``` JavaScript const map = fn => monad => monad.map(fn) const foldMap = fn => monad => monad.foldMap(fn) // 重写前面的例子 const ioEffect = pipe( getLocalStorage, Maybe, map((o) => o.sort((a, b) => b.age - a.age)) map(first) map(prop('name')) foldMap(o => IO(() => writeDom('user')(o))) )('user') ioEffect.runIO() ``` 利用成熟库 现在市场上两个比较成熟的 JavaScript 工具库—— lodash/fp 和 Ramda ,它们所包含的工具函数都实现了柯里化,并且是默认先传函数再传被处理的数据。柯里化再配合上面的 pipe 方法,则可以像下面这样写: ``` JavaScript const arr = [{n: '5'}, {n: '12'}] // 日常写法 arr .map(o => o.n) .map(o => Number(o)) .filter(o => o < 10) // => [5] // 配合 lodash/fp import { map, filter } from 'lodash/fp' pipe( map('n'), Number, filter(o => o < 10) )(arr) ``` 这种写法也叫做 point free,即只考虑函数组合,并不需要考虑参数什么时候传入,因为最终它们会形成一个管道,一头入参,另一头自然就出现结果,而中间的过程是可以任意替换的。 参考: [](https://llh911001.gitbooks.io/mostly-adequate-guide-chinese/content/)<https://llh911001.gitbooks.io/mostly-adequate-guide-chinese/content/> [](https://book.douban.com/subject/30283769/)<https://book.douban.com/subject/30283769/> [](https://egghead.io/lessons/javascript-linear-data-flow-with-container-style-types-box)<https://egghead.io/lessons/javascript-linear-data-flow-with-container-style-types-box> [](https://www.ruanyifeng.com/blog/2017/03/pointfree.html)<https://www.ruanyifeng.com/blog/2017/03/pointfree.html>
长时间使用鼠标导致手腕有点不舒服,所以就考虑全键盘工作的方案,经过一番探索,找到了一个比较适合自己平时工作环境的方案,基本能做到78.9%的工作只用键盘就能完成,右手不用一直键鼠切换。 思路是大量使用快捷键和VSCode Vim,介绍主要分三部分:编码、浏览器、系统。下面详细介绍下需要的工具和常用的快捷键,据我的经验,2、3天就能上手了。 一、编码 > 我没直接用vim,而是使用VSCode的vim插件。是因为要完整配置一套适用当前工作环境的vim插件,非常麻烦,有些用起来甚至不如VSCode自带的,在用Vim开发完一个小项目后我就放弃了。还有一个原因是在windows打造一个好用的命令行工具也很麻烦。总之是烦上加烦。 VSCode常用快捷键 - Ctrl-e:资源管理器 - Ctrl-f/Ctrl-F:当前文件搜索文字/全局搜索文字 - Ctrl-[N]:切换回第N个编辑窗口 - Ctrl-p:搜索并打开文件 - Ctrl-.:打开自动修复菜单 - Ctrl-`:唤起/收起终端 > 快捷键文档:https://code.visualstudio.com/shortcuts/keyboard-shortcuts-windows.pdf VSCode Vim插件 - Vim是一个功能强大的编辑器,不了解的话可以看看[这个](https://www.runoob.com/linux/linux-vim.html) - Vim常用的三种模式: - 普通模式:默认模式,主要用于光标移动(在任意模式按Esc或Ctrl-c会返回普通模式) - 输入模式:输入文字内容(快捷键:i) - 选中模式:选择文字(快捷键:v) - 普通模式常用按键(大部分选中模式也通用) - j/k/h/l:上下左右(文件资源管理器里也可以通过这个快捷键移动,左右快捷键分别对应进入上级/下级文件) - N+移动:数字加上面的移动键可以一次跳多行 - w/b/e/ge:以单词为长度移动 - ^/$:移动光标至行首/行尾 - d:删除,按两下d则是删除当前行,可配合上面的移动操作,删除其他位置 - gg/G:文档最前/最后 - gd:查看/进入引用 - c/d/y i ( :修改/剪切/复制()内的字符,其他如“”、<>等成对符号同样可以这样操作 - za:折叠/收起当前代码块 - space2+w/b/e/ge:将光标快速移动到可见范围内任意处 > 这个插件默认推荐设置space为leader键,leader键就是跟Ctrl一样的前缀键,可以设置成任意一个按键,用于丰富按键组合  - q[a-z]: 录制操作,并命名为a-z中的一个字母,再按一次q就停止录制,@[a-z]则是执行所录制的操作 ,更多高级的操作可以看下文档 - :%s/[old]/[new]/[gci]:全局将[old]替换为[new],g表示全局,c标识每个替换都需要手动确认,i表示查找不区分大小写 - Ctrl-o/Ctrol-i:移动光标到上/下一个位置,即前进后退 - ys[motion][替换字符]:在某个动作选取的范围内添加围绕字符,这个motion是指类似w/b这种具有光标跳转能力的动作 > 文档:https://github.com/VSCodeVim/Vim/blob/master/ROADMAP.md --- 二、浏览器 Vimium插件 这个插件提供大量快捷键用于浏览器的各种交互,强大到可以应付大部分场景,但毕竟浏览器是图形界面工具,所以有很多地方还是无法完全依靠键盘,比如有双滚动条、拖拽类交互的场景 常用命令: - j/k/h/l:上下左右滚动 - u/d:上下翻页 - f/F:唤出所有可点击的地方快捷键,如是可跳转链接,小写是当前页,大写是新开页面 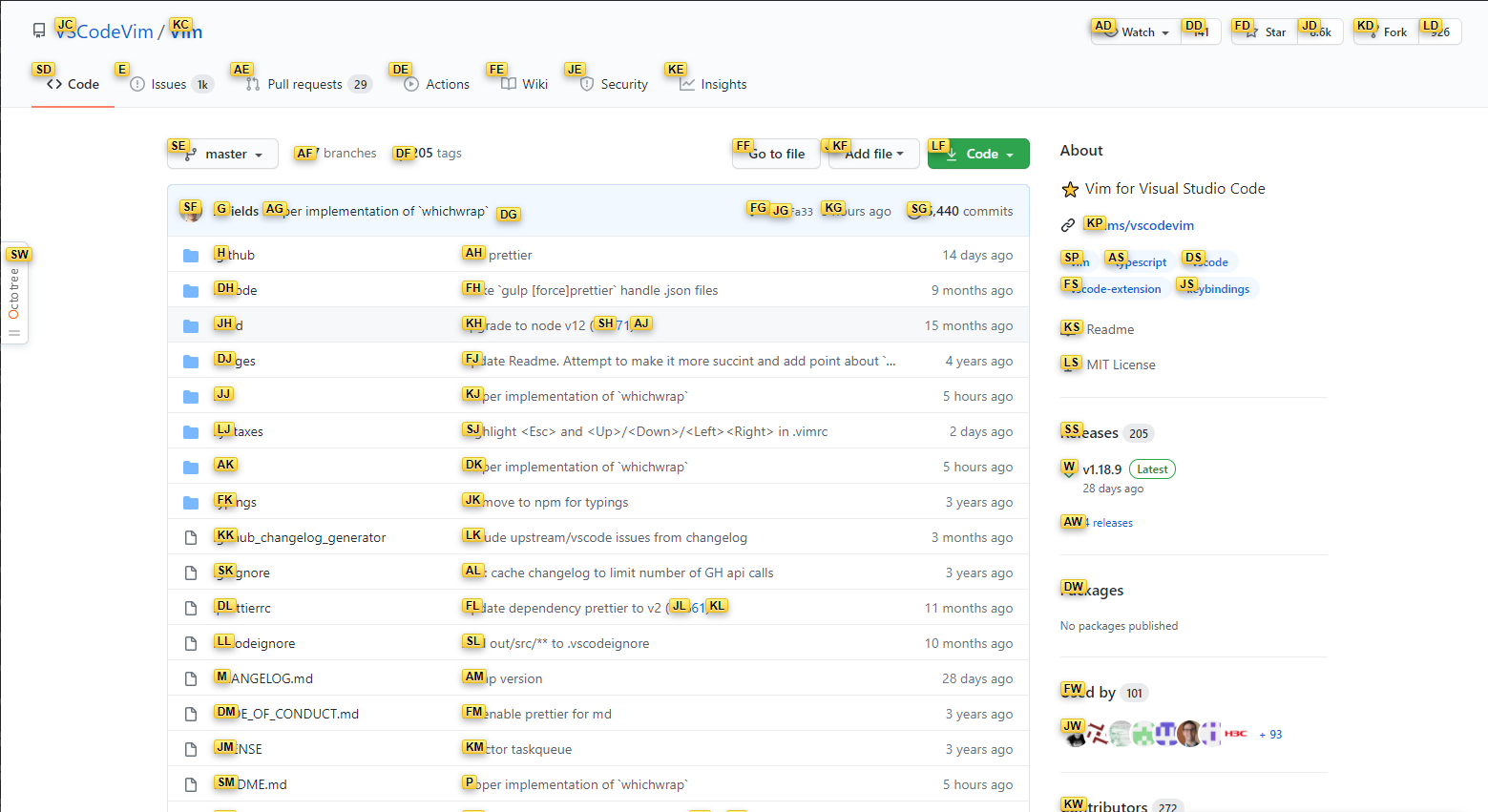 - J/K:左/右切换tab - yy:复制当前网址 - gg/G:滚动至顶部/底部 - o:搜索书签和历史记录 - yy:复制当前网址 > 下面是完整快捷键表  --- 三、系统(windows) - 任务窗口切换:win+数字(窗口在任务栏的排序位置),建议将常用软件固定在任务栏 - 将任务窗口调至左/右:win+左/右方向键,配合[PowerToys](https://github.com/microsoft/PowerToys)效果更好(下图),PowerToys除了窗口布局外,还有键盘映射、文件预览/批处理等功能 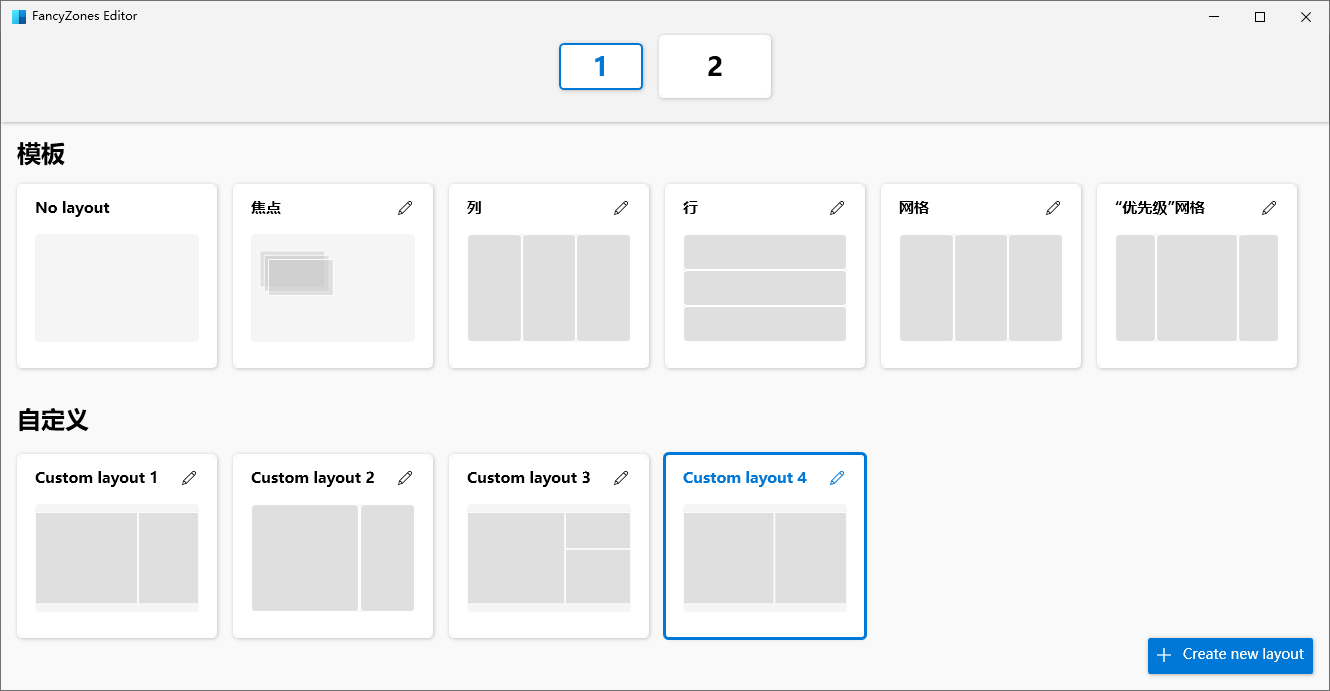 - Ctrl+Shift+w:切换至企业微信,再按一次则进入最新未读一个消息窗口,并自动聚焦输入框(一般其他通讯软件也可设置) - [uTools](https://u.tools/):有丰富插件的生产力工具 - 推荐功能:超级面板,配合众多插件,或者自己写的脚本,一键呼出,贼方便 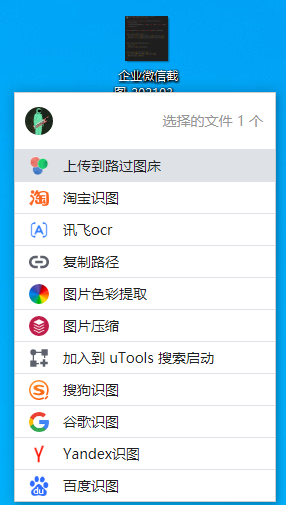 - 插件推荐:图床上传(配合超级面板如上图)、markdown编辑器、自动化助手(脚本)、变量名翻译等 > 如果是mac,推荐[Apptivate](http://www.apptivateapp.com/),可以自定义快捷键切换应用,方便多应用全屏切换。 这个方案,唯一有学习成本的就是Vim的输入方式,可能一开始不太习惯,但是记住几个常用快捷键后很快就能上手,熟练后,速度能比切换键鼠来的快。 有一个建议,使用这套解决方案里,很多时候需要频繁使用Esc键,所以我把Esc和Caps键对调了,感觉挺好用的。 纯键盘操作,还有一个好处,就是哪怕你浏览网页摸鱼,在其他人看来你也是在认真地敲击键盘。
> 原文:[Inside look at modern web browser (part 1)](https://developers.google.com/web/updates/2018/09/inside-browser-part1) CPU, GPU, 内存, 以及多进程架构 这个系列共有4篇,我们将会从Chrome浏览器的高层架构谈到到渲染管道的细节。如果你曾好奇浏览器是怎么将你的代码生成网页,或者你不清楚一些性能优化的实践是建立在哪些原理上的,那这个系列就是为你而准备的。 翻译|揭示现代浏览器原理(1) — Chrome官方 在这一篇,我们将会谈一些关于计算核心的术语和Chrome的多进程架构。 > ★ 提醒:如果你对CPU/GPU的概念和进程/线程这些概念比较熟悉,可以跳到[浏览器架构](浏览器架构)的部分 CPU和GPU是计算机的核心 为了更好了解浏览器运行的环境,我们需要先讲讲计算的部分构成以及它们的作用。 CPU 首先是中央处理器,英文简称CPU。可以理解为计算机的大脑,由若干个核(即运算单元)组成。可以把CPU的核想象成一个社畜,当接到不同的任务时,他会一个一个地去处理(如下图)。从数学计算到图形处理,只要他知道如何处理你的需求,他都会搞定。以前,大多数CPU都是独立的芯片(即没有集成内存、GPU等),一个核更像是同块芯片内的另一个CPU。现代硬件里,通常都是多核的CPU,并且集成了除计算以外的能力,让手机和电脑拥有更强的算力。 > 注:CPU一般会有多个核,就是市面上宣传的双核、四核等概念。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="//p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/cf5eb0aa84e447cd943656672444e8fa~tplv-k3u1fbpfcp-zoom-1.image"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">CPU的每个核像社畜一样在办公桌上等着任务进来</div> </center> GPU 图形处理单元,英文简称GPU,是计算机的另一个组成部分。不像CPU,GPU则擅长利用多核同时处理单一的任务。通过名字可以知道,它就是为了处理图像而生的。这也就是为什么图像的渲染速度和交互流畅度,经常与“GPU使用”和“GPU支持”这些内容所关联。近些年,利用GPU加速,GPU可以独自完成越来越多的计算工作。 > 这里补充一下,引用网上的通俗比喻,CPU是一个博士啥都懂,显卡是千万个小学生同时计算一个公式。CPU只能一件件的解算,显卡可以千万(上亿)个同时解算。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="//p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/f66c098a9ca3470aba449c137758034c~tplv-k3u1fbpfcp-zoom-1.image"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">许多GPU核拿着扳手,意味着它们每个只能做有限的工作</div> </center> 当你在电脑或手机启动并运行一个应用程序,这个过程需要CPU和GPU来完成,通常这个过程有操作系统的调度机制去处理。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="//p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/2310bc85e4f34216be8b588e3a140fed~tplv-k3u1fbpfcp-zoom-1.image"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">计算机架构分三层:硬件在底层提供能力,操作系统在中间调度,应用程序在最上层运行</div> </center> 通过进程和线程执行程序 在讲浏览器架构前,还有一个概念需要掌握,就是进程与线程。进程可以理解为一个正在运行的程序。线程则存在进程中,去执行进程中程序的各个部分。 当你启动一个程序,就创建了一个进程,这个程序会选择性地创建若干个线程去干活。在运行程序的过程中,操作系统会分配给进程“内存块”,是这个程序私有的内存空间,用来存储程序的相关状态。当你退出程序,则进程消失,操作系统会将它之前占用的内存释放。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="//p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/2616113a72a74c7abab606bb73d437df~tplv-k3u1fbpfcp-zoom-1.image"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">进程是一个盒子,线程则可以想象成盒子里畅游的鱼</div> </center> <center> <br> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="//p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/7b4ce278fc364d2597965023128a8954~tplv-k3u1fbpfcp-zoom-1.image"> <br> <a style="text-decoration: underline;" href="https://developers.google.com/web/updates/images/inside-browser/part1/memory.svg">点击查看动画:使用内存空间并存储应用程序数据的过程</a> <br> <br> </center> 一个进程可以要求操作系统启动另一个进程来运行不同的任务。发生这种情况时,将为新进程分配不同的内存。如果两个进程间需要交换信息,它们可以通过进程间通讯机制(IPC)来实现。许多应用程序都有多进程设计,每个模块功能开一个进程,这样如果一个进程故障了,还能保证其他正常运行。 <center> <br> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="//p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/0daccd195126402ba419c04807f358a6~tplv-k3u1fbpfcp-zoom-1.image"> <br> <a style="text-decoration: underline;" href="https://developers.google.com/web/updates/images/inside-browser/part1/workerprocess.svg">点击查看动画:图解多进程通讯</a> <br> <br> </center> 浏览器架构 那么一个网页浏览器是怎么通过进程和线程构建出来的呢?简单来说,他可以是由一个进程和许多不同的线程组成,也可以是许多不同的进程和一些通过IPC通讯的线程。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="//p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/c32de28b456f496794ad213bd2c06b16~tplv-k3u1fbpfcp-zoom-1.image"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">基于进程/线程的不同浏览器架构</div> </center> 需要说明的是,浏览器架构是没有一个标准的,以上都是两种实现方案,不同浏览器间的架构可能会有天壤之别。 而在这个系列,我们将会针对Chrome浏览器最近版本的架构,用图解的方式来讲解浏览器架构。 浏览器有一个主进程,他与负责其他模块的进程协作。对于渲染进程,它会被创建多次并分配给每个分页(tab)。目前,Chrome的调度机制是尽可能给每个分页单独创建一个渲染进程,现在还在尝试给每个网站创建单独的进程,包括iframe。([详情点击查看](https://developers.google.com/web/updates/2018/09/inside-browser-part1site-isolation)) <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="//p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/6f8b168d67d44762874847804221f312~tplv-k3u1fbpfcp-zoom-1.image"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">Chrome多进程架构:图中渲染进程(Render Process)有多层,表示Chrome创建了多个渲染进程为每个分页服务</div> </center> 进程的分工是怎样的呢? 详见下表: | 进程的分工 || | -------- | ----- | | 浏览器主进程 | 控制着一些交互上的功能,如地址栏、书签、前进后退按钮。当然也包括浏览器底层的控制,如网络请求和文件操作权限 | | 渲染 | 控制分页内,网页展示的一切 | | 插件 | 控制浏览器所使用的插件,如flash | | GPU | 脱离其他进程,单独完成图像处理任务。它还会被分解成多个进程,用于处理不同应用的需求,并将其绘制在同一个面板上 | <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="//p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/3b994078af314cebb004bc7009c9320c~tplv-k3u1fbpfcp-zoom-1.image"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">不同的进程指向不同的模块</div> </center> 还有更多进程没有提到,如扩展程序进程和浏览器工具进程。如果你想看看有哪些进程运行在你的Chrome上,点击右上角菜单按钮 -> 更多工具 -> 任务管理器。就会打开一个窗口展示给你看,现在有哪些进程在运行,分别消耗了多少CPU和内存资源。 Chrome多进程架构的优势 前面,我提到Chrome使用多渲染进程。你想象一下,在大多数情况下,Chrome为每个分页(tab)单独创建一个渲染进程。比如有三个分页,如果其中一个卡住了,那么你可以关掉它,继续使用其他分页。如果所有分页共用一个进程,那很不幸,挂一个全遭殃。 <center> <br> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="//p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/d94a8565d03f4c49beff62480b714213~tplv-k3u1fbpfcp-zoom-1.image"> <br> <a style="text-decoration: underline;" href="https://developers.google.com/web/updates/images/inside-browser/part1/tabs.svg">点击查看动画:分页拥有单独渲染进程</a> <br> <br> </center> 多进程架构另一个优势是安全性和沙盒。因为操作系统提供了限制进程权限的方法,所以浏览器可以将某些进程隔离起来。例如,像渲染进程这种需要处理用户输入的进程,Chrome会限制它对任意文件的访问权限。 因为这些进程都有自己专门的内存空间,他们通常会拷贝一份通用的基础工具库进去(比如Chrome的JavsScript解析引擎V8)。这意味着,如果不是同一进程里的线程则不能共享这些基础工具库,造成了内存浪费。为了减少这种浪费,Chrome对进程的数量会有所限制,具体取决于你设备的CPU和内存。当Chrome开的进程数达到了设定的极限,它会开始将同一个网站的分页(tab)运行在同一个进程中,不再为每个分页单独开进程。 节约更多内存 - Chrome的服务化 Chrome正在进行架构更改,将这个成熟的方案运用在浏览器的进程管理中,以将浏览器程序的每个部分作为一项服务运行,从而可以轻松拆分为不同的进程或聚合为一个进程。 大概就是当Chrome跑在高性能的机子上,它会将功能服务拆分进不同的进程,从而获得更高的稳定性。相反,如果跑在一些“小霸王”上,则将服务聚合到一个进程上以减少内存占用。在Chrome的这次调整之前,Android平台已经运用这套方案将进程合并来降低内存占用。 <center> <br> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="//p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/89b2c559625f48c686b10255e94c13b8~tplv-k3u1fbpfcp-zoom-1.image"> <br> <a style="text-decoration: underline;" href="https://developers.google.com/web/updates/images/inside-browser/part1/servicfication.svg">点击查看动画:服务在多进程和单进程间切换</a> <br> <br> </center> 分站渲染进程 - 站点隔离 [站点隔离](https://developers.google.com/web/updates/2018/07/site-isolation)是最近被引进Chrome的特性,为每个站点(即网站)开一个单独的渲染进程。之前谈到每个分页(tab)单独开一个渲染进程,允许不同站点在其中运行,并共享内存空间。a.com和b.com运行在同一个渲染进程,因为有[同源策略](https://developer.mozilla.org/en-US/docs/Web/Security/Same-origin_policy)的存在,它是web的核心安全模型,它保证了两个站点间在没有对方允许的情况下,不可以传输数据。但这样还是有隐患,网站安全攻击常常会以绕过此安全策略为首要目标,所以解决这种隐患最有效的方案就是站点隔离。再加上出现[溶毁和幽灵漏洞](https://developers.google.com/web/updates/2018/02/meltdown-spectre),就更需要将站通过不同进程分开。从桌面版Chrome 67开始,分页内跨站点的iframe都默认会为其单独开一个渲染线程。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="//p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/acccb4cd0d404df9bdde070566c28f24~tplv-k3u1fbpfcp-zoom-1.image"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">分页内不同站点的iframe都被分配了单独的渲染进程(Render Process)</div> </center> 使站点互相独立是多年工程攻坚的成果,这并不仅仅是分配渲染进程这么简单。它改变了iframe间通信的底层实现,在运行有若干个iframe的页面,每个iframe有自己的进程,当你按F12打开chrome开发者工具时,Chrome后台需要做许多工作才能使开发者工具的启动无缝衔接。哪怕只是简单地用 Ctrl+F 检索全文,也需要通过搜索不同进程中的内容来得到准确结果。这也是为什么浏览器工程师谈起站点隔离时,会说这是个重要的里程碑。 总结一下 这篇文章,我们纵览了浏览器的架构和了解了多进程架构的优势。也看到了Chrome的服务化和站点隔离跟多进程架构的紧密联系。[在下一篇,进程与线程时如何合作去展示一个网页的。](https://developers.google.com/web/updates/2018/09/inside-browser-part2) ```! 如有翻译错误,欢迎指正 ```
> 原文:[Inside look at modern web browser (part 2)](https://developers.google.com/web/updates/2018/09/inside-browser-part2step_1_handling_input) 网页访问过程中发生了什么 这是揭秘浏览器原理系列的第二篇,[在上一篇](https://juejin.im/post/6844904082348441614),我们讲解了浏览器如何利用不同的进程和线程去运作对应功能模块。本文会更深入地探讨不同的进程和线程是如何协作来展示一个网页的。 当你在浏览器输入一个网址,浏览器会从互联网获取倒数据,并将其展示出来。这篇文章将会重点讲用户输入地址到浏览器准备渲染网页的这个过程。 从浏览器主进程开始 在第一篇[CPU、GPU、内存和多进程架构](https://developers.google.com/web/updates/2018/09/inside-browser-part1)中,我们提到tab页以外的一切都在浏览器的主进程中运转。浏览器的主进程里包括有负责绘制导航栏上按钮和输入框等UI的线程,有负责网络数据获取的线程,有控制文件操作权限的存储线程等。当你输入一个URL到地址栏时,这个输入过程是由浏览器主进程中的UI线程来处理。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/17197016382ebfbb?w=865&h=504&f=png&s=62722"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">UI线程、存储线程和网络处理线程</div> </center> 网页访问 第一步:处理输入 当用户在地址栏输入时,UI线程需要先知道输入的是搜索关键词还是URL?在谷歌浏览器里,地址栏同时也是搜索框,所以UI线程会先解析输入内容,再决定是跳转搜索引擎还是输入的地址。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/1719701632d32bc1?w=865&h=504&f=png&s=52557"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">UI线程判断是搜索关键词还是URL</div> </center> 第二步:开始跳转 当用户按下回车键,UI线程会将网址传给网络处理线程,让其初始化网络调用准备去拿网页内容。这时当前tab标签的一角会有加载中的菊花动画,网络线程则要通过一系列协议,如DNS查询和建立TLS连接来发起请求。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/171970163326d427?w=865&h=504&f=png&s=63579"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">UI线程通知网络处理线程将要跳转到mysite.com</div> </center> 有时候,网络处理线程也许会从服务器那收到一个重定向的响应头,如HTTP 301(永久重定向)。在这种情况下,网络处理进程会告知UI线程服务器请求重定向,接下来,另一个URL请求将会被初始化。 第三步:读取响应数据 拿到响应数据后,网络线程将在必要时查看数据流前面的若干个字节。响应头的Content-Type(媒体类型)字段会说明这是什么类型的数据,如果这个字段不存在,则会进行媒体类型嗅探,[源码](https://cs.chromium.org/chromium/src/net/base/mime_sniffer.cc?sq=package:chromium&dr=CS&l=5)里的注释说嗅探这个操作很棘手,因为需要考虑很多东西。如果你想了解不同的浏览器是如何处理媒体类型和数据有效载荷的,你可以去看一下源码的注释。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/171970163f067269?w=720&h=363&f=png&s=37422"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">在响应头中的Content-Type(媒体类型)和有payload(有效载荷,即真正需要用到的数据)</div> </center> 如果请求返回的是HTML文件,那下一步就是将其传给渲染进程。但如果是压缩文件或其他类型的文件,则意味着这是个下载文件的请求,那就要将文件数据交给下载管理器了。 这个环节还会做[浏览安全检测](https://safebrowsing.google.com/),如果域名或返回数据跟系统黑名单匹配上了,那网络处理线程会展示一个警告页面。并且,跨域限制检查也会触发,以保证跨域敏感数据不会进入渲染线程。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/1719701633ddfbd7?w=865&h=504&f=png&s=67622"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">网络线程判断返回数据是否为HTML?并来自安全的站点</div> </center> 第四步:准备渲染进程 一旦所有的检查都通过了,网络线程确定目标网站是安全的,就会告诉UI线程所有数据都准备就绪了。接下来,UI线程就会让已经初始化好的渲染进程开始处理页面。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/171970164b395809?w=865&h=504&f=png&s=68929"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">网络线程告诉UI线程可以开始让渲染进程工作了</div> </center> 因为网路线程去请求数据通常需要几百毫秒,为了充分利用这个时间空档,当在第二步UI线程将URL传给网络线程后,UI线程就马上异步地去为这个URL查找或创建一个渲染进程。如果一切进行顺利,则这个准备好的渲染进程就能在网络请求完成后立马开始工作。但如果进行了跨站重定向,则之前预先准备的渲染进程将不会被使用,而是针对新的网址重新创建。 第五步:完成跳转 当数据和渲染进程都准备好了,浏览器主进程会通过IPC(进程间通信)通信,把HTML数据以数据流的方式持续传输给渲染进程。一旦浏览器主进程收到渲染进程接受完毕的确认后,这次跳转就完成了,进入文档加载阶段。 此时,地址栏会更新,网站安全标示和网站设置UI会根据当前网站的信息来显示。tab的访问历史会更新,也就是前进/后退键会去到之前访问过的地方。为了保证tab的访问记录之后还能恢复,这个历史记录将会保存进硬盘。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/171970171f502c98?w=865&h=504&f=png&s=79984"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">浏览器住进程和渲染进程件的IPC(进程间通信)</div> </center> 额外的步骤:初始化加载完成 跳转完成后,渲染进程还需要继续加载资源和渲染页面。在[下一篇文章](https://developers.google.com/web/updates/2018/09/inside-browser-part3)中,我们将详细介绍此阶段发生的情况。当渲染进程“结束”渲染,它会通过IPC(进程间通信)告知浏览器主进程(这是在所有onload函数,包括iframe内的,都执行完毕后才进行的通信)。收到信息后,浏览器主进程内的UI线程将会停止tab上的loading的菊花动画。 上面说“结束”带了双引号,是因为客户端的JavaScript此时依然可以加载额外的资源和渲染新的试图。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/1719701720fd24be?w=865&h=504&f=png&s=69282"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">渲染进程告诉浏览器主进程加载完成</div> </center> 跳转至不同的站点 至此,一个简单的网页访问完成了。但如果用户在地址栏再输入一个不同的URL会怎么样呢?当然,浏览器进程还是会走跟上面同样的步骤。但在此之前,它需要检查当前网页是否有声明 [beforeunload](https://developer.mozilla.org/en-US/docs/Web/API/Window/beforeunload_event) 事件。 在你关闭tab页时,beforeunload事件中可能会写有一些提醒之类的代码,如“是否确定离开此页”。tab下的所有东西包括JavaScript代码都是由渲染进程处理的,所以浏览器主进程在跳转其他页面时,需要检查一下这个渲染进程内是否声明了这个事件。 > 注意:如非必要,不要随便声明 beforeunload 事件,因为只有在执行完这个事件后才能跳转下一个页面,所以在此事件里添加了一些无条件执行的内容可能会造成潜在问题。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/171970172584612d?w=865&h=504&f=png&s=78337"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">浏览器主进程告诉渲染进程需要跳转另一个页面了</div> </center> 如果跳转是在渲染进程里发起的(比如用户点击跳转链接或JavaScript运行了```window.location = "https://newsite.com"```),渲染进程会先检查 beforeunload 事件,接下来就是走之前同样的步骤。唯一不同的是,这次跳转是由渲染进程去通知浏览器主进程。 当跳转到另一个站点,会加入另一个渲染进程来处理。当前的渲染进程还需要做一些收尾工作,如触发 unload 事件。更多内容,可以查看[页面生命周期一览](https://developers.google.com/web/updates/2018/07/page-lifecycle-apioverview_of_page_lifecycle_states_and_events)和通过[页面生命周期API](https://developers.google.com/web/updates/2018/07/page-lifecycle-api)了解如何使用钩子函数。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/1719701725d62e2b?w=865&h=504&f=png&s=86452"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">浏览器主进程让新的渲染进程开始渲染,让老的结束</div> </center> 如果有Service Worker 跳转过程最近有一个新改动就是引入了[service worker](https://developers.google.com/web/fundamentals/primers/service-workers)。service worker可以让你在应用里搭建一个网络代理,方便控制需要缓存的数据和数据的新鲜度。如果service worker设置了可以读缓存,那就没必要去请求网络数据了。 但问题是,service worker是运行在渲染进程中的JavaScript代码,当访问一个网页时,浏览器主进程怎么知道是否存在service worker呢? <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/17197017325498da?w=877&h=540&f=png&s=43019"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">浏览器主进程中的网络线程在询问是否有service worker</div> </center> 当一个service worker被注册,它的作用域将被保存为一个引用。(更多关于作用域的信息可以参考这篇:[service worker生命周期](https://developers.google.com/web/fundamentals/primers/service-workers/lifecycle))跳转页面时,网络处理线程通过注册的service worker作用域去检查这个域名下是否注册有service worker,如果有就会引入渲染进程让它去执行service worker的代码。接下来,这个service worker开始运行,可能会从缓存取旧数据,免去请求,或者去请求新数据。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/171970177c95cba0?w=865&h=504&f=png&s=79091"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">UI线程开启一个渲染进程去处理service worker;而渲染进程内的那个worker线程开始请求网络数据</div> </center> 导航预载 你可以想象一下,如果service worker最终需要请求网络数据,那浏览器主进程和这个渲染进程间的频繁通信会有很大延迟。而[导航预载](https://developers.google.com/web/updates/2017/02/navigation-preload)就是优化此问题的一个机制,它可以在service worker启动的同时异步地去加载资源。你在头部声明需要的请求,就会允许服务器为这些请求发送不同的内容,如只更新数据而不是整个文档。 <center> <img style="border-radius: 0.3125em; box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);" src="https://user-gold-cdn.xitu.io/2020/4/20/17197017f98829d2?w=865&h=504&f=png&s=73160"> <br> <div style="color:orange; border-bottom: 1px solid d9d9d9; display: inline-block; color: 999; padding: 2px;">UI线程启动了一个渲染进程来处理service worker,同时通知网络线程异步请求数据</div> </center> 总结 这篇文章,我们了解了跳转过程中的细节,和你的网页应用里响应头、客户端JavaScript等,是如何与浏览器交互的。说明了浏览器获取网络数据的步骤,让你更容易了解像导航预载这种API的作用。[下一篇](https://developers.google.com/web/updates/2018/09/inside-browser-part3)我们将会深入了解浏览器是如何执行HTML/CSS/JavaScript来渲染页面的。 ```! 如有翻译错误,欢迎指正 ```